Inference Endpoints
An inference endpoint serves a checkpoint over HTTP. It is a persistent deployment that mounts a checkpoint read-only, loads the model, and exposes a stable URL with a health check. Unlike a fine-tuning job, an endpoint runs until you stop it.
Roadmap
Inference endpoints are the serving half of Token Factory. This page documents the intended behavior. Refer to your installation’s release notes for current availability.Prerequisites
- A checkpoint produced by a
completedfine-tuning job.
Creating an endpoint
You pick the checkpoint to serve, the GPU instance to serve it on, and the serving parameters below. The platform renders a serving configuration, stands up a persistent deployment that mounts the checkpoint read-only, and exposes it at a stable subdomain with a health check.
Serving parameters
| Parameter | Meaning |
|---|---|
| Checkpoint | The checkpoint to serve. Must belong to your organization. |
| GPU instance | The GPU instance to serve on. |
| Max context | Maximum context length the endpoint will accept. |
| Precision | Serving precision (for example bfloat16). |
| Quantization | Optional serving-time quantization. |
Using an endpoint
Once the endpoint is healthy, send requests to its URL. The endpoint exposes a health check so the platform (and you) can tell when it is ready to serve. The model stays loaded for the life of the endpoint, so there is no per-request cold start once it is running.
The endpoint detail page shows its connection details, serving configuration, recent activity, and an example request.
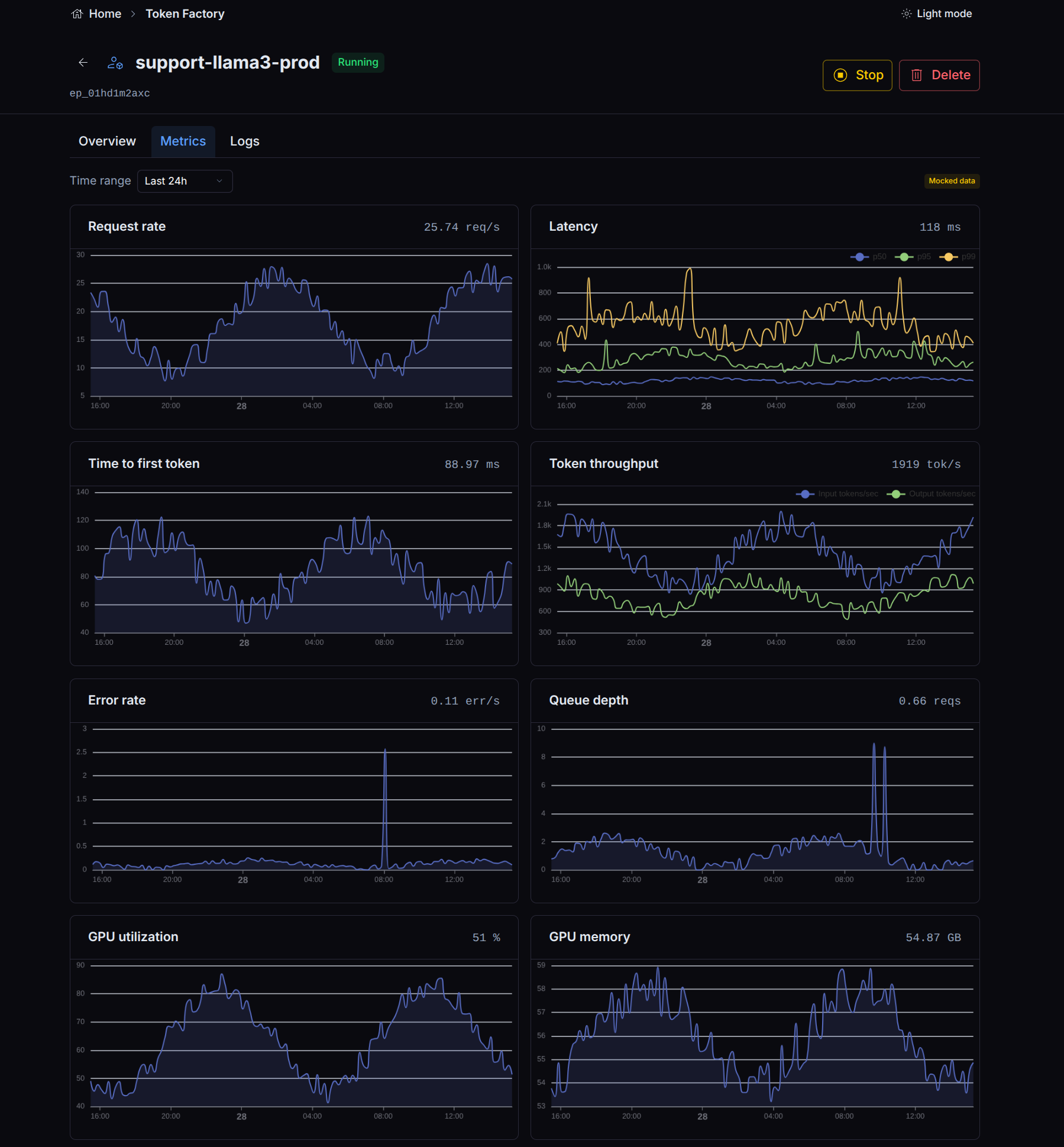
A Metrics tab tracks request rate, latency, time to first token, token throughput, and GPU use over time.
Managing endpoints
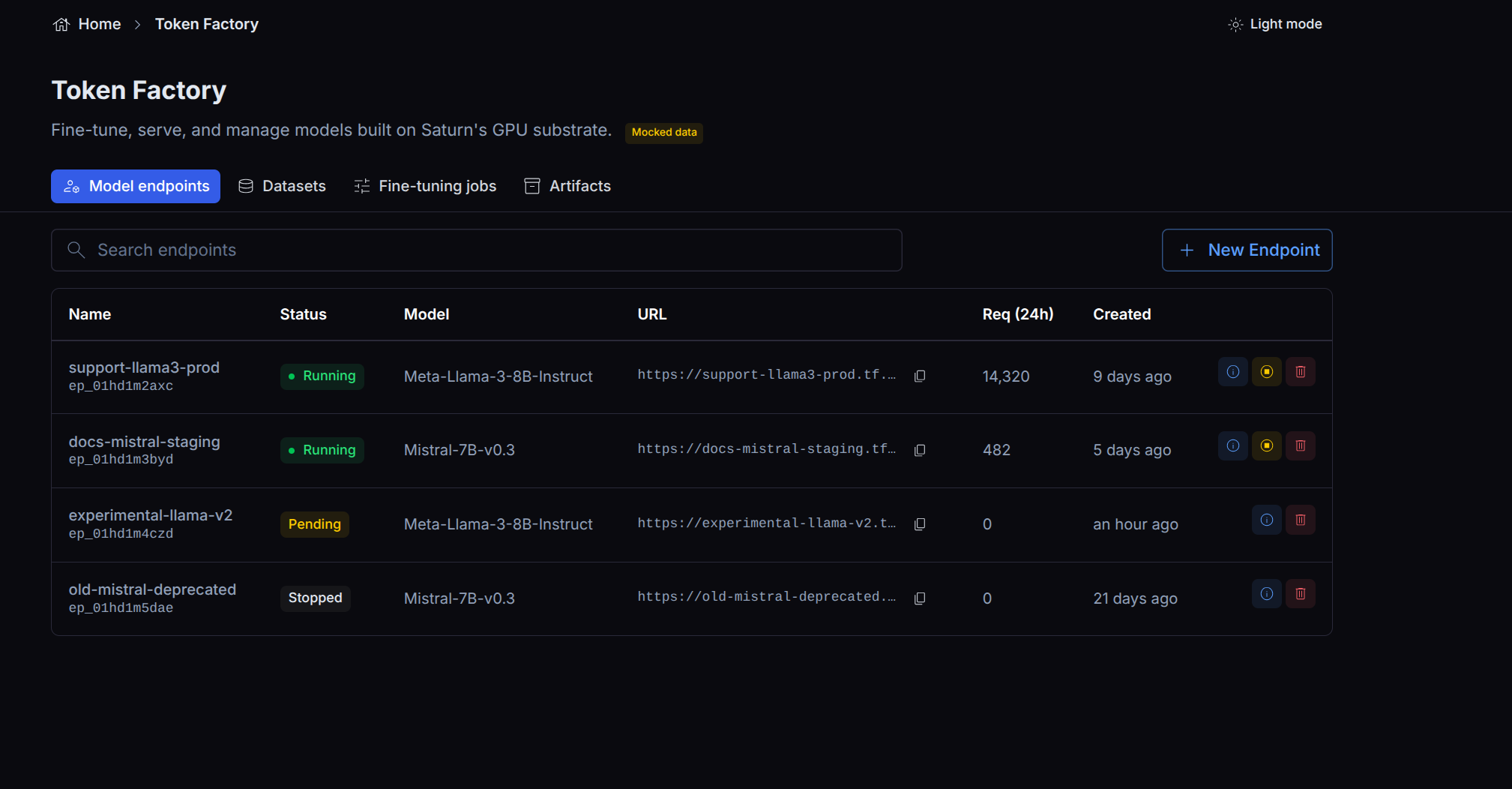
Token Factory lists your endpoints with their status, and lets you stop and remove an endpoint when you no longer need it.
Lifecycle and the checkpoint
An endpoint holds a read-only reference to its checkpoint for as long as it runs. A checkpoint that an endpoint is actively serving cannot have its underlying bytes reclaimed: deletion of a checkpoint with active consumers is blocked, and byte reclamation only happens once every endpoint that read it has stopped. This means you can delete a checkpoint record without disrupting an endpoint that is still serving it; the cleanup waits for the endpoint to go away.
Cost
An inference endpoint is a persistent GPU deployment. It consumes its GPU instance for as long as it runs, whether or not it is receiving traffic. Stop endpoints you are not using. For workloads that do not need a model resident at all times, a fine-tuning job or a batch Job may fit better.