Concepts
Token Factory has four objects. Three are things you create directly (datasets, fine-tuning jobs, inference endpoints); one is produced for you (checkpoints). This page describes each and the relationships between them.
Objects
Dataset
A dataset is a named, immutable collection of training examples registered with the platform.
The bytes live on shared organization storage; the platform keeps a catalog entry that records the
dataset’s name, format, status, and metadata. A dataset has a status that moves from
assembling (you are still writing data into it) to ready (sealed and usable by a job).
Once sealed, a dataset’s contents do not change.
Datasets are typed by format (for example conversational, instruction, plain text, or
pretokenized .jsonl). The format determines what validation runs at ingest and which base
models the data is appropriate for. The platform stores the format and any derived metadata
(row count, schema type, checksum) but does not reinterpret the bytes after ingest.
Fine-tuning job
A fine-tuning job is a single GPU training run. You give it a base model, a dataset, and a set
of hyperparameters; the platform renders a complete training configuration, schedules the job
on an appropriate GPU instance, and runs it to completion. A job has a status that reflects the
underlying run (pending, running, stopping, stopped, completed, error).
You do not write a training script. The hyperparameters you submit (learning rate, epochs, effective batch size, max sequence length, LoRA rank and alpha) are the entire interface. The platform translates them into the underlying trainer configuration and reports them back to you unchanged on the job view.
Checkpoint
A checkpoint is the output of a successful fine-tuning job: the trained weights plus the metadata needed to serve them. You do not create checkpoints directly. A job produces at most one checkpoint, registered automatically when training finishes. Each checkpoint records which job produced it, so you can trace a served model back to the exact run and hyperparameters that created it.
If a job fails, no usable checkpoint is produced. The job view reflects the failure and the checkpoint field stays empty.
Inference endpoint
An inference endpoint is a persistent deployment that serves a checkpoint over HTTP. It mounts the checkpoint read-only, loads the model, and exposes a stable URL with a health check. Unlike a fine-tuning job, an endpoint runs until you stop it.
How they relate
- A dataset must be
ready(sealed) before a job can use it. - A fine-tuning job reads exactly one dataset and produces at most one checkpoint.
- A checkpoint is tied to the job that produced it and can back one or more endpoints.
- An inference endpoint reads one checkpoint and keeps reading it while running.
Lineage
Every object carries enough information to reconstruct the chain:
- A checkpoint records its producing job.
- A job records the dataset it trained on and the hyperparameters it ran with (read back from the rendered configuration, so the numbers you see always match the numbers you submitted).
- An endpoint records the checkpoint it serves.
This means that from a running endpoint you can answer “which weights is this serving, from which training run, on which dataset, with which hyperparameters” without keeping a separate record yourself.
Datasets and checkpoints both appear in the artifact registry, which records each artifact’s kind, status, size, producer, and location.
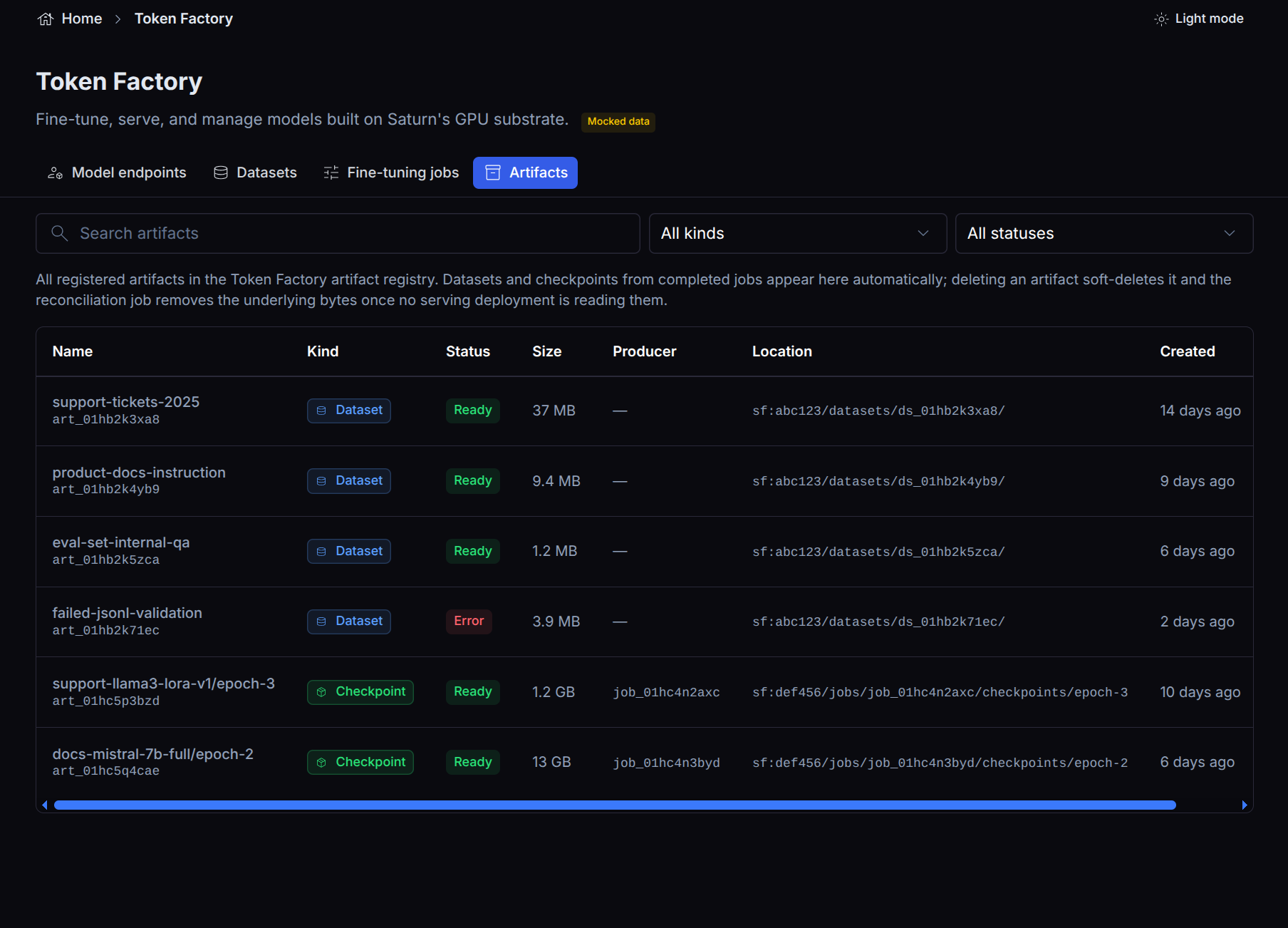
Ownership and visibility
All Token Factory objects are owned by your organization and visible to every member of it. Datasets and checkpoints are read-only to ordinary users: you can list them, inspect them, and mount a dataset into a workspace for analysis, but you cannot overwrite the canonical copy that Token Factory manages. This keeps the catalog trustworthy. The thing you trained on is the thing the record says you trained on.