Load Data From S3 Buckets
Overview
If you use AWS S3 to store your data, connecting to Saturn Cloud takes just a couple of steps.
In this example we use s3fs to connect to data, but you can also use libraries like boto3 if you prefer.
Before starting this, you should create a Jupyter server resource. See our quickstart if you don’t know how to do this yet.
Process
To connect to public S3 buckets, you can simply connect using anonymous connections in Jupyter, the way you might with your local laptop. In this case, you can skip to the Connect to Data Via s3fs section.
If your S3 data storage is not public and requires AWS credentials, please read on!
Create AWS Credentials
Credentials for S3 access can be acquired inside your AWS account. Visit https://aws.amazon.com/ and sign in to your account.
In the top right corner, click the dropdown under your username and select My Security Credentials.
![]()
Under “My Security Credentials” you’ll see section titled “Access keys for CLI, SDK, & API access”. If you don’t yet have an access key listed, create one.

Save the key information that this generates, and keep it in a safe place!
Add AWS Credentials to Saturn Cloud
Sign in to your Saturn Cloud account and select Credentials from the menu on the left.
This is where you will add your S3 API key information. This is a secure storage location, and it will not be available to the public or other users without your consent.
At the top right corner of this page, you will find the New button. Click here, and you will be taken to the Credentials Creation form.
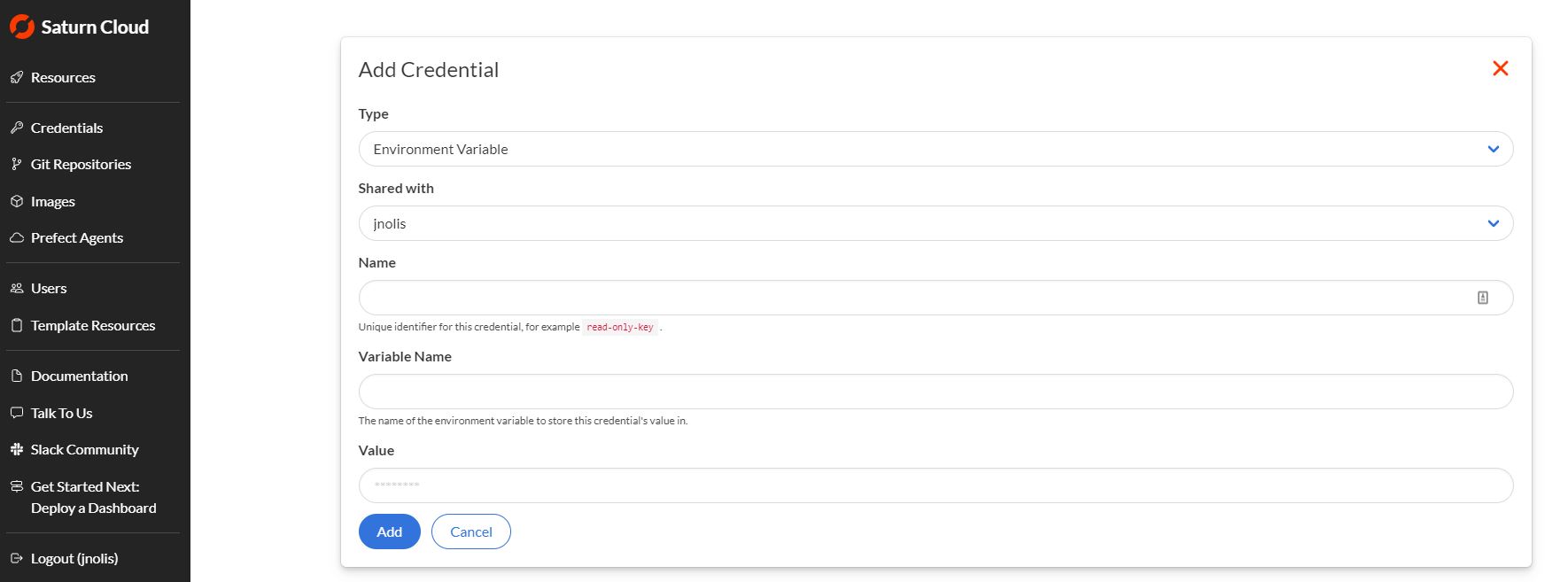
You will be adding three credentials items: your AWS Access Key, AWS Secret Access Key, and you default region. Complete the form one time for each item.
| Credential | Type | Name | Variable Name |
|---|---|---|---|
| AWS Access Key ID | Environment Variable | aws-access-key-id | AWS_ACCESS_KEY_ID |
| AWS Secret Access Key | Environment Variable | aws-secret-access-key | AWS_SECRET_ACCESS_KEY |
| AWS Default Region | Environment Variable | aws-default-region | AWS_DEFAULT_REGION |
Copy the values from your AWS console into the Value section of the credential creation form. The credential names are recommendations; feel free to change them as needed for your workflow. You must, however, use the provided Variable Names for S3 to connect correctly.
With this complete, your S3 credentials will be accessible by Saturn Cloud resources! You will need to restart any Jupyter Server or Dask Clusters for the credentials to populate to those resources.
Connect to Data Via s3fs
Set Up the Connection
Normally, s3fs will automatically seek your AWS credentials from the environment. Since you have followed our instructions above for adding and saving credentials, this will work for you!
If you don’t have credentials and are accessing a public repository, set anon=True in the s3fs.S3FileSystem() call.
import s3fs
s3 = s3fs.S3FileSystem(anon=False)
At this point, you can reference the s3 handle and look at the contents of your S3 bucket as if it were a local file system. For examples, you can visit the s3fs documentation where they show multiple ways to interact with files like this.
Load a Parquet file using pandas
This approach just uses routine pandas syntax.
import pandas as pd
file = "saturn-public-data/nyc-taxi/data/yellow_tripdata_2019-01.parquet
with s3.open(file, mode="rb") as f:
df = pd.read_parquet(f)
For small files, this approach will work fine. For large or multiple files, we recommend using Dask, as described next.
Load a Parquet file using Dask
This syntax is the same as pandas, but produces a distributed data object.
import dask.dataframe as dd
file = "saturn-public-data/nyc-taxi/data/yellow_tripdata_2019-01.parquet"
with s3.open(file, mode="rb") as f:
df = dd.read_parquet(f)
Load a folder of Parquet files using Dask
Dask can read and load a whole folder of files if they are formatted the same, using glob syntax.
files = s3.glob("s3://saturn-public-data/nyc-taxi/data/yellow_tripdata_2019-*.parquet")
taxi = dd.read_parquet(
files,
storage_options={"anon": False},
assume_missing=True,
)