Run a Prefect Cloud Data Pipeline on a Single Machine

Overview
Prefect Cloud is a hosted, high-availability, fault-tolerant service that handles all the orchestration responsibilities for running data pipelines. It gives you complete oversight of your workflows and makes it easy to manage them.
This example shows how to create a project and execute tasks synchronously in the main thread (without using parallel computing). We will then register this flow with Prefect Cloud so that service can be used for orchestrating when the flow runs.
Model Details
The data used for this example is the “Incident management process enriched event log” dataset from the UCI Machine Learning Repository.This dataset contains tickets from an IT support system, including characteristics like the priority of the ticket, the time it was opened, and the time it was closed.
We will use this dataset in our example to solve following regression task:
Given the characteristics of a ticket, how long will it be until it is closed?
We wil then evaluate the performance of above model, that predicts time-to-close for tickets in an IT support system.
Modelling Process
Prerequisites
- created a Prefect Cloud account
- set up the appropriate credentials in Saturn
- set up a Prefect Cloud agent in Saturn Cloud
Details on these prerequisites can be found in Using Prefect Cloud with Saturn Cloud.
Environment Setup
Prefect Cloud data pipeline execution can be done 3 ways in Saturn Cloud :
- On a Single Machine : You can run your code on a single node using local executor, which is default option in Saturn Cloud for running Prefect workflows. This is how we will be executing our pipeline in this example.
- Distributing tasks across dasak clusters. Refer prefect-daskclusters example for this.
- Parallelizng a task over dask clusters. Refer prefect-resource-manager example.
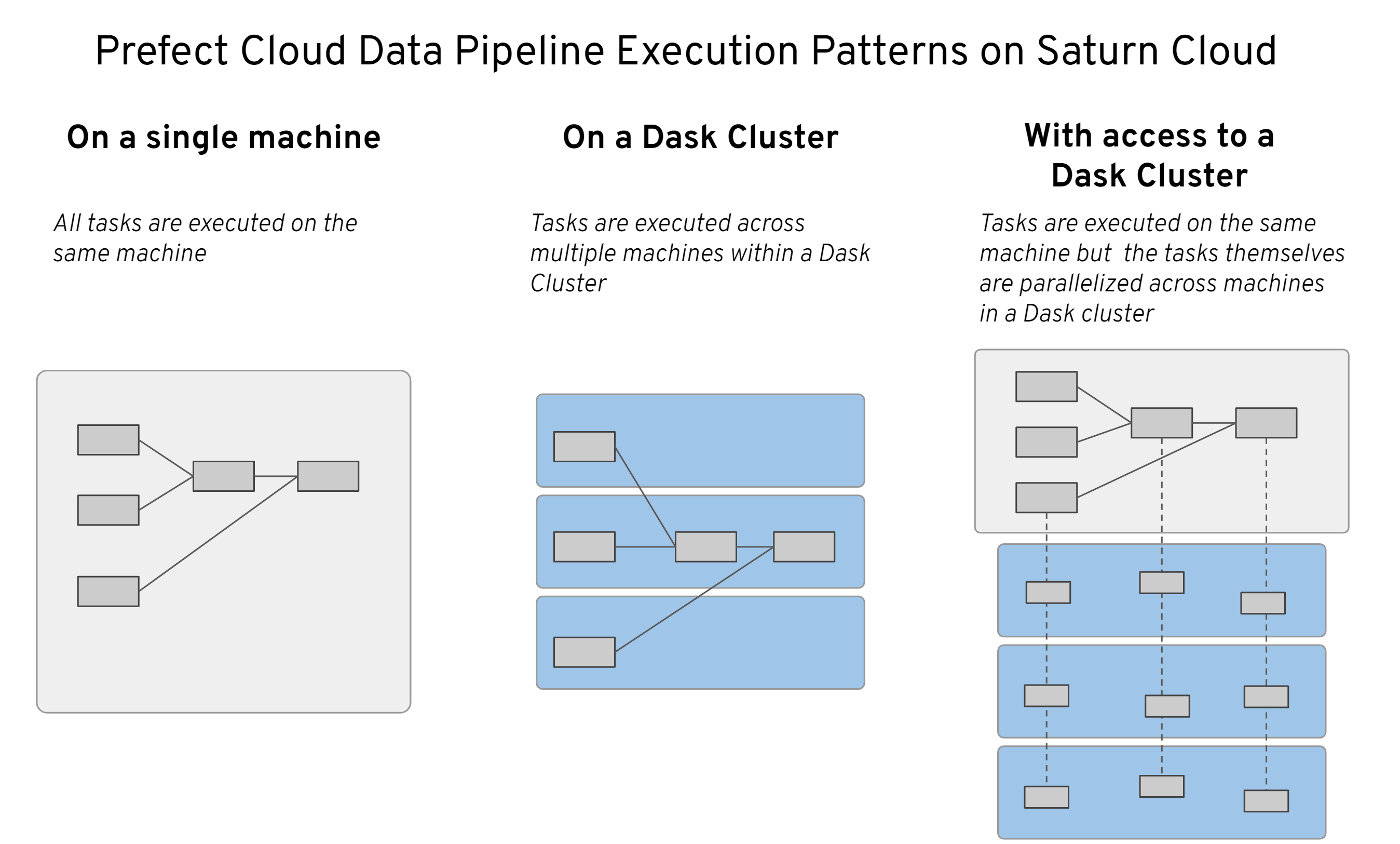
The code in this example uses prefect for orchestration (figuring out what to do, and in what order) and local executor for execution (doing the things).
It relies on the following additional non-builtin libraries:
- numpy: data manipulation
- pandas: data manipulation
- requests: read in data from the internet
- scikit-learn: evaluation metric functions
- prefect-saturn: register Prefect flows with both Prefect Cloud and Saturn Cloud.
import json
import os
import uuid
from datetime import datetime, timedelta
from io import BytesIO
from zipfile import ZipFile
import numpy as np
import pandas as pd
import requests
from prefect.schedules import IntervalSchedule
from sklearn.metrics import (
mean_absolute_error,
mean_squared_error,
median_absolute_error,
r2_score,
)
import prefect
from prefect import Flow, Parameter, task
PREFECT_CLOUD_PROJECT_NAME = os.environ["PREFECT_CLOUD_PROJECT_NAME"]
SATURN_USERNAME = os.environ["SATURN_USERNAME"]
Authenticate with Prefect Cloud.
!prefect auth login --key ${PREFECT_USER_TOKEN}
Create a Prefect Cloud Project
Prefect Cloud organizes flows within workspaces called “projects”. Before you can register a flow with Prefect Cloud, it’s necessary to create a project, if you don’t have one yet.
The code below will create a new project in whatever Prefect Cloud tenant you’re authenticated with. If that project already exists, this code does not have any side effects.
client = prefect.Client()
client.create_project(project_name=PREFECT_CLOUD_PROJECT_NAME)
Define Tasks
Prefect refers to a workload as a “flow”, which comprises multiple individual things to do called “tasks”. From the Prefect docs:
A task is like a function: it optionally takes inputs, performs an action, and produces an optional result.
The goal of this notebook’s flow is to evaluate, on an ongoing basis, the performance of a model that predicts time-to-close for tickets in an IT support system.
That can be broken down into the following tasks
get_trial_id(): assign a unique ID to each runget_ticket_data_batch(): get a random set of newly-closed ticketsget_target(): given a batch of tickets, compute how long it took to close thempredict(): predict the time-to-close, using the heuristic “higher-priority tickets close faster”evaluate_model(): compute evaluation metrics comparing predicted and actual time-to-closeget_trial_summary(): collect all evaluation metrics in one objectwrite_trial_summary(): write trial results somewhere
@task
def get_trial_id() -> str:
"""
Generate a unique identifier for this trial.
"""
return str(uuid.uuid4())
@task
def get_ticket_data_batch(batch_size: int) -> pd.DataFrame:
"""
Simulate the experience of getting a random sample of new tickets
from an IT system, to test the performance of a model.
"""
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00498/incident_event_log.zip"
resp = requests.get(url)
zipfile = ZipFile(BytesIO(resp.content))
data_file = "incident_event_log.csv"
# _date_parser has to be a lambda or pandas won't convert dates correctly
_date_parser = lambda x: pd.NaT if x == "?" else datetime.strptime(x, "%d/%m/%Y %H:%M")
df = pd.read_csv(
zipfile.open(data_file),
parse_dates=[
"opened_at",
"resolved_at",
"closed_at",
"sys_created_at",
"sys_updated_at",
],
infer_datetime_format=False,
converters={
"opened_at": _date_parser,
"resolved_at": _date_parser,
"closed_at": _date_parser,
"sys_created_at": _date_parser,
"sys_updated_at": _date_parser,
},
na_values=["?"],
)
df["sys_updated_at"] = pd.to_datetime(df["sys_updated_at"])
rows_to_score = np.random.randint(0, df.shape[0], 100)
return df.iloc[rows_to_score]
@task
def get_target(df):
"""
Compute time-til-close on a data frame of tickets
"""
time_til_close = (df["closed_at"] - df["sys_updated_at"]) / np.timedelta64(1, "s")
return time_til_close
@task
def predict(df):
"""
Given an input data frame, predict how long it will be until the ticket is closed.
For simplicity, using a super simple model that just says
"high-priority tickets get closed faster".
"""
seconds_in_an_hour = 60.0 * 60.0
preds = df["priority"].map(
{
"1 - Critical": 6.0 * seconds_in_an_hour,
"2 - High": 24.0 * seconds_in_an_hour,
"3 - Moderate": 120.0 * seconds_in_an_hour,
"4 - Lower": 240.0 * seconds_in_an_hour,
}
)
default_guess_for_no_priority = 180.0 * seconds_in_an_hour
preds = preds.fillna(default_guess_for_no_priority)
return preds
@task
def evaluate_model(y_true, y_pred, metric_name: str) -> float:
metric_func_lookup = {
"mae": mean_absolute_error,
"medae": median_absolute_error,
"mse": mean_squared_error,
"r2": r2_score,
}
metric_func = metric_func_lookup[metric_name]
return metric_func(y_true, y_pred)
@task
def get_trial_summary(trial_id: str, actuals, input_df: pd.DataFrame, metrics: dict) -> dict:
out = {"id": trial_id}
out["data"] = {
"num_obs": input_df.shape[0],
"metrics": metrics,
"target": {
"mean": actuals.mean(),
"median": actuals.median(),
"min": actuals.min(),
"max": actuals.max(),
},
}
return out
@task(log_stdout=True)
def write_trial_summary(trial_summary: str):
"""
Write out a summary of the file. Currently just logs back to the
Prefect logger
"""
logger = prefect.context.get("logger")
logger.info(json.dumps(trial_summary))
Construct a Flow
Now that all of the task logic has been defined, the next step is to compose those tasks into a “flow”. From the Prefect docs:
A Flow is a container for Tasks. It represents an entire workflow or application by describing the dependencies between tasks.
Flows are DAGs, or “directed acyclic graphs.” This is a mathematical way of describing certain organizational principles:
- A graph is a data structure that uses “edges” to connect “nodes.” Prefect models each Flow as a graph in which Task dependencies are modeled by Edges.
- A directed graph means that edges have a start and an end: when two tasks are connected, one of them unambiguously runs first and the other one runs second.
- An acyclic directed graph has no circular dependencies: if you walk through the graph, you will never revisit a task you’ve seen before.
If you want to run this job to run on a schedule, include “schedule” object as one additional argument to Flow(). In this case, the code below says “run this flow once every 24 hours”.
schedule = IntervalSchedule(interval=timedelta(hours=24))
*NOTE: prefect flows do not have to be run on a schedule. If you want to run prefect flows on a schedule add schedule=schedule as an additional argument to Flow() in code below.
with Flow(f"{SATURN_USERNAME}-ticket-model-evaluation") as flow:
batch_size = Parameter("batch-size", default=1000)
trial_id = get_trial_id()
# pull sample data
sample_ticket_df = get_ticket_data_batch(batch_size)
# compute target
actuals = get_target(sample_ticket_df)
# get prediction
preds = predict(sample_ticket_df)
# compute evaluation metrics
mae = evaluate_model(actuals, preds, "mae")
medae = evaluate_model(actuals, preds, "medae")
mse = evaluate_model(actuals, preds, "mse")
r2 = evaluate_model(actuals, preds, "r2")
# get trial summary in a string
trial_summary = get_trial_summary(
trial_id=trial_id,
input_df=sample_ticket_df,
actuals=actuals,
metrics={"MAE": mae, "MedAE": medae, "MSE": mse, "R2": r2},
)
# store trial summary
trial_complete = write_trial_summary(trial_summary)
Register with Prefect Cloud
Now that the business logic of the flow is complete, we can add information that Saturn Cloud will need to know to run it.
from prefect.executors import LocalExecutor
from prefect_saturn import PrefectCloudIntegration
# tell Saturn Cloud about the flow
integration = PrefectCloudIntegration(prefect_cloud_project_name=PREFECT_CLOUD_PROJECT_NAME)
flow = integration.register_flow_with_saturn(flow=flow)
# override the executor chosen by prefect-saturn
flow.executor = LocalExecutor()
Next, run `register_flow_with_saturn().
register_flow_with_saturn() does a few important things:
- specifies how and where the flow’s code is stored so it can be retrieved by a Prefect Cloud agent (see flow.storage)
- specifies the infrastructure needed to run the flow. In this case, it uses a KubernetesJobEnvironment
The final step necessary is to “register” the flow with Prefect Cloud. If this is the first time you’ve registered this flow, it will create a new Prefect Cloud project PREFECT_CLOUD_PROJECT_NAME. If you already have a flow in this project with this name, it will create a new version of it in Prefect Cloud.
# tell Prefect Cloud about the flow
flow.register(project_name=PREFECT_CLOUD_PROJECT_NAME)
Run the Flow
If you have scheduled your flow, it will be run once every 24 hours. You can confirm this by doing all of the following:
- If you are an admin, go to Prefect Cloud Agent page of Saturn Cloud which is at the side bar and check logs for your agent.
- Go to Prefect Cloud. If you navigate to this flow and click “Runs”, you should see task statuses and logs for this flow.
If you have not scheduled your flow or want to run the flow immediately, navigate to the flow in the Prefect Cloud UI and click “Quick Run”.
An alternative way to run the flow immediately is to open a terminal and run the code below.
prefect auth login --key ${PREFECT_USER_TOKEN}
prefect run \
--name ${SATURN_USERNAME}-ticket-model-evaluation \
--project ${PREFECT_CLOUD_PROJECT_NAME}
Conclusion
Prefect makes your workflows more managable and fault tolerant. In this example, you learned how to execute all tasks locally in a single thread with Prefect and register this flow with Prefect Cloud.Often your tasks have complex computations or dataset is huge. For such cases you can distribute work across Dask clusters. Check our examples for distributing single and multiple tasks across Dask Clusters.
import json
import os
import uuid
from datetime import datetime, timedelta
from io import BytesIO
from zipfile import ZipFile
import numpy as np
import pandas as pd
import requests
from prefect.schedules import IntervalSchedule
from sklearn.metrics import (
mean_absolute_error,
mean_squared_error,
median_absolute_error,
r2_score,
)
import prefect
from prefect import Flow, Parameter, task
PREFECT_CLOUD_PROJECT_NAME = os.environ["PREFECT_CLOUD_PROJECT_NAME"]
SATURN_USERNAME = os.environ["SATURN_USERNAME"]
!prefect auth login --key ${PREFECT_USER_TOKEN}
client = prefect.Client()
client.create_project(project_name=PREFECT_CLOUD_PROJECT_NAME)
@task
def get_trial_id() -> str:
"""
Generate a unique identifier for this trial.
"""
return str(uuid.uuid4())
@task
def get_ticket_data_batch(batch_size: int) -> pd.DataFrame:
"""
Simulate the experience of getting a random sample of new tickets
from an IT system, to test the performance of a model.
"""
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/00498/incident_event_log.zip"
resp = requests.get(url)
zipfile = ZipFile(BytesIO(resp.content))
data_file = "incident_event_log.csv"
# _date_parser has to be a lambda or pandas won't convert dates correctly
_date_parser = lambda x: pd.NaT if x == "?" else datetime.strptime(x, "%d/%m/%Y %H:%M")
df = pd.read_csv(
zipfile.open(data_file),
parse_dates=[
"opened_at",
"resolved_at",
"closed_at",
"sys_created_at",
"sys_updated_at",
],
infer_datetime_format=False,
converters={
"opened_at": _date_parser,
"resolved_at": _date_parser,
"closed_at": _date_parser,
"sys_created_at": _date_parser,
"sys_updated_at": _date_parser,
},
na_values=["?"],
)
df["sys_updated_at"] = pd.to_datetime(df["sys_updated_at"])
rows_to_score = np.random.randint(0, df.shape[0], 100)
return df.iloc[rows_to_score]
@task
def get_target(df):
"""
Compute time-til-close on a data frame of tickets
"""
time_til_close = (df["closed_at"] - df["sys_updated_at"]) / np.timedelta64(1, "s")
return time_til_close
@task
def predict(df):
"""
Given an input data frame, predict how long it will be until the ticket is closed.
For simplicity, using a super simple model that just says
"high-priority tickets get closed faster".
"""
seconds_in_an_hour = 60.0 * 60.0
preds = df["priority"].map(
{
"1 - Critical": 6.0 * seconds_in_an_hour,
"2 - High": 24.0 * seconds_in_an_hour,
"3 - Moderate": 120.0 * seconds_in_an_hour,
"4 - Lower": 240.0 * seconds_in_an_hour,
}
)
default_guess_for_no_priority = 180.0 * seconds_in_an_hour
preds = preds.fillna(default_guess_for_no_priority)
return preds
@task
def evaluate_model(y_true, y_pred, metric_name: str) -> float:
metric_func_lookup = {
"mae": mean_absolute_error,
"medae": median_absolute_error,
"mse": mean_squared_error,
"r2": r2_score,
}
metric_func = metric_func_lookup[metric_name]
return metric_func(y_true, y_pred)
@task
def get_trial_summary(trial_id: str, actuals, input_df: pd.DataFrame, metrics: dict) -> dict:
out = {"id": trial_id}
out["data"] = {
"num_obs": input_df.shape[0],
"metrics": metrics,
"target": {
"mean": actuals.mean(),
"median": actuals.median(),
"min": actuals.min(),
"max": actuals.max(),
},
}
return out
@task(log_stdout=True)
def write_trial_summary(trial_summary: str):
"""
Write out a summary of the file. Currently just logs back to the
Prefect logger
"""
logger = prefect.context.get("logger")
logger.info(json.dumps(trial_summary))
schedule = IntervalSchedule(interval=timedelta(hours=24))
with Flow(f"{SATURN_USERNAME}-ticket-model-evaluation") as flow:
batch_size = Parameter("batch-size", default=1000)
trial_id = get_trial_id()
# pull sample data
sample_ticket_df = get_ticket_data_batch(batch_size)
# compute target
actuals = get_target(sample_ticket_df)
# get prediction
preds = predict(sample_ticket_df)
# compute evaluation metrics
mae = evaluate_model(actuals, preds, "mae")
medae = evaluate_model(actuals, preds, "medae")
mse = evaluate_model(actuals, preds, "mse")
r2 = evaluate_model(actuals, preds, "r2")
# get trial summary in a string
trial_summary = get_trial_summary(
trial_id=trial_id,
input_df=sample_ticket_df,
actuals=actuals,
metrics={"MAE": mae, "MedAE": medae, "MSE": mse, "R2": r2},
)
# store trial summary
trial_complete = write_trial_summary(trial_summary)
from prefect.executors import LocalExecutor
from prefect_saturn import PrefectCloudIntegration
# tell Saturn Cloud about the flow
integration = PrefectCloudIntegration(prefect_cloud_project_name=PREFECT_CLOUD_PROJECT_NAME)
flow = integration.register_flow_with_saturn(flow=flow)
# override the executor chosen by prefect-saturn
flow.executor = LocalExecutor()
# tell Prefect Cloud about the flow
flow.register(project_name=PREFECT_CLOUD_PROJECT_NAME)
