Deploying LLMs with NVIDIA NIM
NVIDIA NIM (NVIDIA Inference Microservices) is a platform designed to simplify and accelerate the deployment of AI models, particularly for generative AI applications like large language models (LLMs), chatbots, and digital humans. It provides developers with pre-built, optimized inference microservices that can be deployed across various infrastructures, including cloud platforms, data centers, and workstations.
NIM’s core functionality revolves around allowing developers to deploy and manage AI models with minimal complexity. It integrates seamlessly with industry-standard APIs and popular AI frameworks like PyTorch, TensorRT, and NVIDIA NeMo, making it easy to fine-tune or customize models for specific use cases. With these microservices, developers can leverage pre-trained models or deploy their own customized models at scale, ensuring high performance and low latency.
To deploy NVIDIA NIM, please contact support@saturncloud.io to enable NIM for your Saturn Cloud installation. Next, select the NIM you would like to deploy.
Once the NIM has booted, you can access the NIM at the following URL.
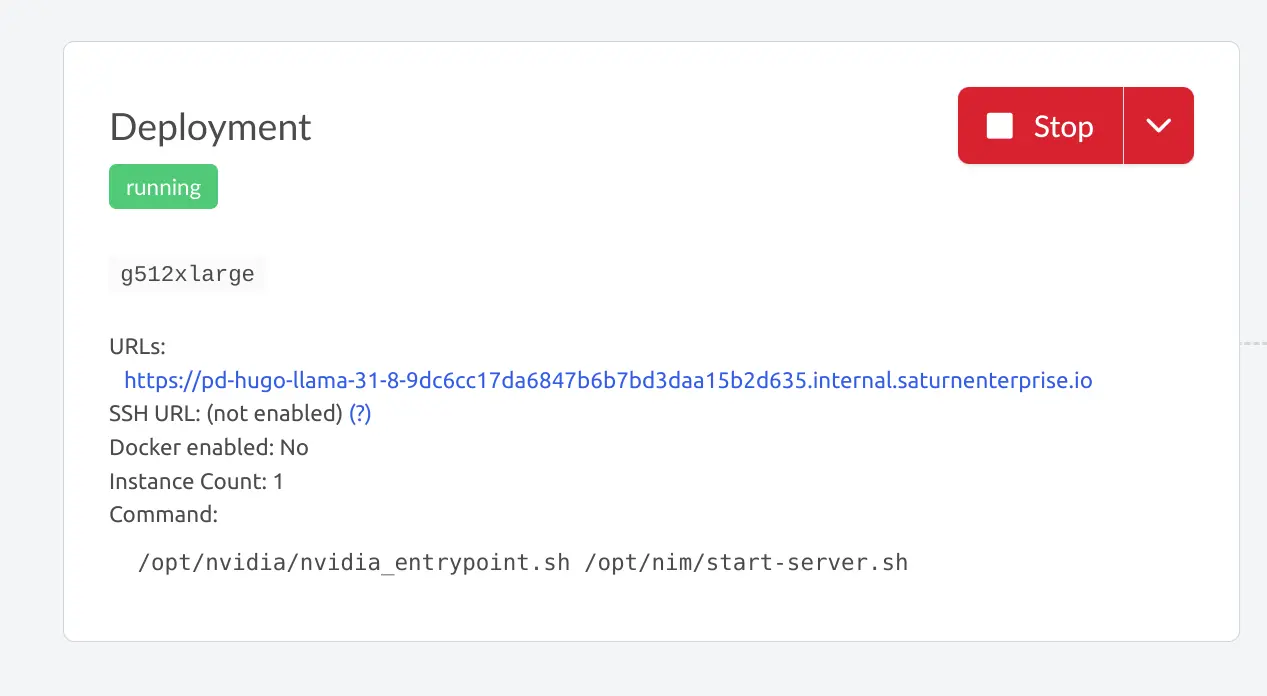
Please see the section on deployments to understand how to authenticate with this deployment, as well as restrict access to it.
