Saturn Cloud on Nebius
Saturn Cloud Enterprise for Nebius provides a fully managed data science platform deployed directly into your Nebius AI Infrastructure environment. Saturn Cloud Enterprise has a standard configuration for Nebius AI Infrastructure. In a typical installation, we provision a Nebius Managed Kubernetes (MK8S) cluster in your Nebius project, integrate it with your existing VPC and subnet, and configure CPU and GPU node pools optimized for data science workloads. Saturn Cloud is hosted publicly with secure authentication by default, with private networking options available if required.
This standard installation creates a ready-to-use platform for machine learning and AI workloads with GPU acceleration. Beyond the default setup, Saturn Cloud can customize node pool sizes, GPU configurations, and network settings to meet your organization’s needs.
Architecture Overview
Saturn Cloud on Nebius leverages Nebius Managed Kubernetes (MK8S) to provide a scalable, secure, and managed platform for data science teams.
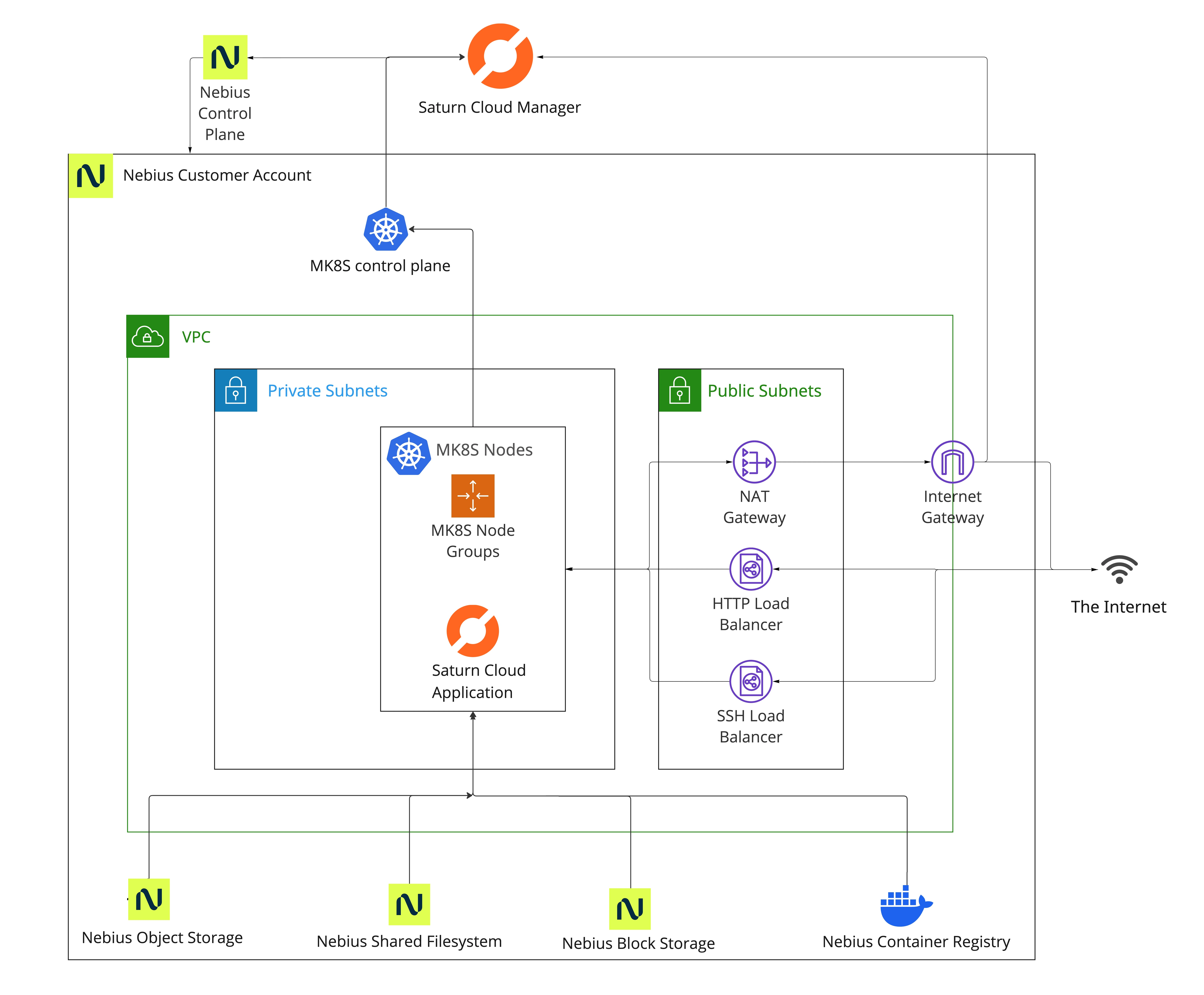
The infrastructure includes:
Core Components
- MK8S Cluster: A managed Kubernetes cluster with version 1.30 and integrated container registry access
- VPC Network: Integration with Nebius VPC and subnet infrastructure for network isolation
- Node Pools: Auto-scaling node groups optimized for different workload types, including GPU-accelerated nodes
- Storage: Integration with Nebius storage services for persistent data storage
- Container Registry: Secure access to Nebius Container Registry (NCR) for container images
Network Architecture
Saturn Cloud integrates with your existing Nebius VPC infrastructure:
1. Network Integration
Network integration ensures that Saturn Cloud is deployed seamlessly within your existing Nebius VPC and subnet configuration.
- Existing VPC: Utilizes your pre-configured Nebius VPC and subnet
- Subnet Integration: Deployed within your specified subnet ID for controlled network placement
- Public Endpoints: Cluster control plane accessible via public endpoints with secure authentication
- Regional Deployment: Supports deployment in Nebius regions (eu-north1 primary)
2. Network Security
The Nebius deployment ensures:
- Integration with existing VPC security controls
- Controlled access through IAM and service accounts
- Secure container registry access via group memberships
- Kubernetes-native network policies for workload isolation
Node Pool Architecture
The installation creates specialized node pools optimized for AI and data science workloads.
Note
The node pool configurations below are optimized for Nebius AI Infrastructure. Saturn Cloud can customize these configurations to match your specific requirements, including:
- Different CPU and memory presets
- Custom GPU configurations
- Specific availability zone preferences
- Tailored autoscaling limits
- Specialized platforms (CPU-optimized, GPU-accelerated)
Contact support@saturncloud.io to discuss customization options for your deployment.
1. System Node Pool
The system node pool is dedicated to running Saturn Cloud’s control plane and core system services.
- Purpose: Runs Saturn Cloud control plane and system services
- Platform: cpu-d3 (latest generation CPU platform)
- Preset: 4vcpu-16gb (4 vCPUs, 16GB RAM)
- Scaling: 2-100 nodes
- Disk: 93GB Network SSD (non-replicated)
2. CPU Node Pools
Saturn Cloud provisions multiple CPU-optimized node pools for various computational requirements:
Large Instances (nebius-large)
- Platform: cpu-d3
- Preset: 4vcpu-16gb (4 vCPUs, 16GB RAM)
- Use Case: General purpose workloads, development environments
- Auto-scaling: 0-100 nodes
2XLarge Instances (nebius-2xlarge)
- Platform: cpu-d3
- Preset: 16vcpu-64gb (16 vCPUs, 64GB RAM)
- Use Case: Memory-intensive analytics, data processing
- Auto-scaling: 0-100 nodes
4XLarge Instances (nebius-4xlarge)
- Platform: cpu-d3
- Preset: 64vcpu-256gb (64 vCPUs, 256GB RAM)
- Use Case: Large-scale computational workloads, big data processing
- Auto-scaling: 0-100 nodes
3. GPU Node Pools
Saturn Cloud provides access to Nebius AI Infrastructure’s GPU fleet, including NVIDIA H200, A100, and other high-performance GPUs. Our standard configuration showcases H200 SXM configurations, though Saturn Cloud can provision any GPU type available in Nebius’s infrastructure to meet your specific requirements.
Single H200 GPU (1xh200)
- Platform: gpu-h200-sxm
- Preset: 1gpu-16vcpu-200gb (1x H200 GPU, 16 vCPUs, 200GB RAM)
- GPU Memory: 141GB HBM3e per GPU
- Use Case: Model inference, development, single-GPU training
- Auto-scaling: 0-100 nodes
8x H200 GPU (8xh200)
- Platform: gpu-h200-sxm
- Preset: 8gpu-128vcpu-1600gb (8x H200 GPUs, 128 vCPUs, 1600GB RAM)
- GPU Memory: 1.128TB total HBM3e (8x 141GB)
- Use Case: Large-scale model training, distributed deep learning, LLM training
- Auto-scaling: 0-100 nodes
GPU Fleet Access
The H200 configurations shown above represent our reference implementation. Nebius AI Infrastructure offers additional GPU types including A100 and other high-performance options. Contact support@saturncloud.io to discuss accessing Nebius’s complete GPU portfolio for your specific workload requirements.NVIDIA H200 Advantages
The NVIDIA H200 GPUs provide exceptional performance for AI workloads:
- 141GB HBM3e memory per GPU - 2.4x more memory than A100
- 4.8TB/s memory bandwidth - Superior performance for memory-intensive workloads
- FP8 precision support - Optimized for transformer models and LLMs
- NVLink connectivity - High-speed GPU-to-GPU communication for multi-GPU training
Security Features
Saturn Cloud on Nebius is deployed with multiple security controls to protect access, data, and workloads:
- Service Account Authentication: Dedicated service accounts for secure cluster and registry access
- IAM Group Integration: Automated membership management for container registry permissions
- Workload Identity: Kubernetes-native service account to IAM mapping
- Network Policies: Fine-grained network segmentation within the cluster
- Encrypted Storage: Network SSD with built-in encryption
- Secure Endpoints: TLS-encrypted control plane and API access
Storage and Data Access
Saturn Cloud leverages Nebius storage and registry services to ensure reliable data access and high availability:
- Network SSD: High-performance, non-replicated storage for boot disks
- Persistent Volumes: Dynamic provisioning through CSI drivers
- Container Registry: Integrated access to Nebius Container Registry
- Multi-Zone: Support for multi-zone deployments for high availability
Monitoring and Operations
Operational features in Saturn Cloud automate scaling, resource allocation, and system health management:
- Cluster Autoscaling: Automatic node provisioning based on workload demands
- GPU Scheduling: Automatic GPU resource allocation and scheduling
- Health Monitoring: Continuous monitoring of node and cluster health
- Automatic Updates: Managed Kubernetes updates and security patches
Installation Process
Saturn Cloud Enterprise for Nebius is fully managed. The installation steps are:
Prerequisites
- Nebius Project Setup: Ensure you have a Nebius project with appropriate permissions
- Network Configuration: Have your VPC and subnet configured and note the subnet ID
- IAM Groups: Identify your viewers group ID for container registry access
Installation Steps
Prepare Service Account Credentials: Set up Nebius service account with required environment variables:
export NB_AUTHKEY_PRIVATE_PATH="/path/to/private/key" export NB_AUTHKEY_PUBLIC_ID="your-public-key-id" export NB_SA_ID="your-service-account-id"Configure Installation Parameters: Provide the following information to Saturn Cloud support:
# Your Nebius project ID project_id = "project-xxxxxxxxxxxxxxxxxx" # The subnet ID where the cluster will be deployed subnet_id = "vpcsubnet-xxxxxxxxxxxxxxxxxx" # The ID of the viewers group for container registry access viewers_group_id = "group-xxxxxxxxxxxxxxxxxx" # Name for your Kubernetes cluster cluster_name = "my-saturn-cluster"Grant Installation Access: Provide Saturn Cloud support with the necessary service account permissions
Installation Deployment: Our team will handle the infrastructure deployment using Terraform
Access Your Installation: Receive your Saturn Cloud URL and admin credentials
Getting Started
Ready to transform your AI capabilities? contact our team to discuss your specific requirements and get started with a custom deployment.
Next Steps:
- Discovery Call: Discuss your AI infrastructure needs and current challenges
- Custom Architecture: Design an optimized deployment for your workloads
- Rapid Deployment: Get up and running in your Nebius environment within days
- Ongoing Support: 24/7 monitoring and optimization of your AI infrastructure
Limited Availability
H200 GPU capacity is limited and in high demand. Contact support@saturncloud.io today to secure your allocation and avoid delays in your AI initiatives.Ongoing Management
Saturn Cloud Enterprise on Nebius is fully managed, meaning:
- Automatic Kubernetes updates and security patches
- 24/7 monitoring and support for both CPU and GPU workloads
- Performance optimization for AI/ML workloads
- NVIDIA driver updates and GPU health monitoring
- Backup and disaster recovery
- Scaling optimization based on workload patterns
Regional Availability
Saturn Cloud on Nebius can be deployed in regions where Nebius AI Infrastructure is available:
- eu-north1 (Finland) - Primary region with H200 GPU availability
- Additional regions as Nebius expands GPU infrastructure
Cost Optimization
The Nebius infrastructure uses several cost optimization strategies:
- Auto-scaling to Zero: All node pools except system nodes can scale to zero when unused
- Efficient Resource Allocation: Right-sized presets for different workload types
- GPU Optimization: Automatic GPU scheduling prevents resource waste
- Network SSD: Cost-effective storage with high performance
- Resource Tagging: Detailed cost allocation through Kubernetes labels
- Idle Detection: Automatic shutdown of unused GPU resources
Performance Advantages
Saturn Cloud on Nebius provides unique performance benefits:
- Next-generation GPU access - H200, A100, and other high-performance GPUs with exceptional memory capacity
- High-Speed Networking - Optimized for multi-GPU and distributed training
- CPU-D3 Platform - Latest generation CPU architecture
- Memory-Optimized Configurations - Large memory allocations for big data workloads
- Container Registry Integration - Fast image pulls for rapid scaling
