Deploy Your Machine Learning Model - Part 3 (Flask API or Web App)
In the final part of this three part series we cover how to take a trained model and deploy it as an API.

You can get lots of value from Dask without even using a distributed cluster. Try using the LocalCluster instead!
Read article →
In the final part of this three part series we cover how to take a trained model and deploy it as an API.

In part two of this three part series we cover how to take a trained model and make an interactive web app from it.

In part one of this three part series we cover how to train a model to deploy as a dashboard or API.

How you can automate your complex tasks using Saturn Cloud, Dask, and Prefect
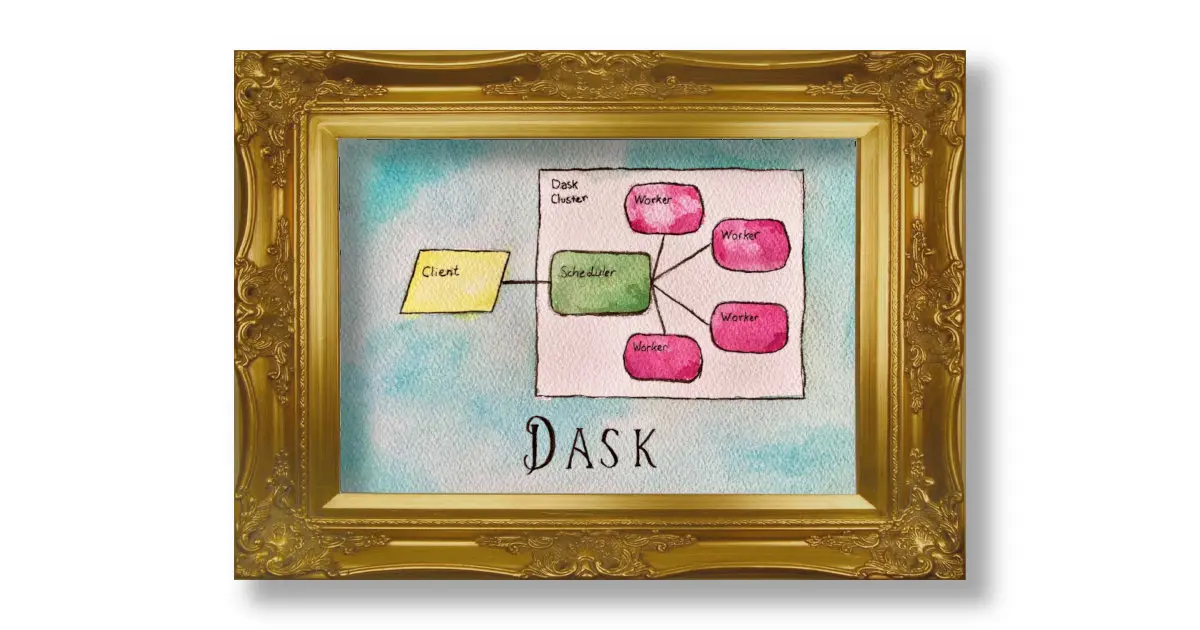
While Saturn Cloud provides client resources to connect to Dask clusters, you can also directly connect from external locations.

Weights & Biases is a great tool for monitoring model training performance. And it works with Saturn Cloud!
The basics of what Dask is, why you'd want to use it, and how to get started.

Do you love pandas, but hate when you reach the limits of your memory or compute resources? Dask gives you the chance to use the pandas …

Lazy evaluation is when calculations are only computed when they are needed, and Dask makes great use of the method.