This article was published when data science tooling like Dask and R was a primary focus for Saturn Cloud. Today, Saturn Cloud is the enterprise AI platform for any GPU infrastructure.
GPU computing is the future of data science. Packages such as RAPIDS, TensorFlow, and PyTorch enable lightning-fast processing for all facets of data science: data cleaning, feature engineering, machine learning, deep learning, and more. The challenge with taking advantage of GPU computing is that it requires investment for on-premise hardware or infrastructure build-outs to utilize GPUs on the cloud.
Today, Saturn Cloud is announcing the launch of Saturn Cloud Hosted, a cloud-hosted solution for end-to-end GPU Data Science that fits the needs of all startups, small teams, students, researchers, and tinkering data scientists.
Within seconds of signing up, you can spin up a Jupyter Lab instance with pre-configured environments for the most popular GPU data science packages, backed by an NVIDIA T4 or V100 GPU. When your data size exceeds that of a single GPU, you can easily scale out to a cluster of multiple GPU machines. Hundreds even! Saturn Hosted takes care of all the hardware provisioning, environment setup, and cluster communication challenges so data scientists can get straight to work.
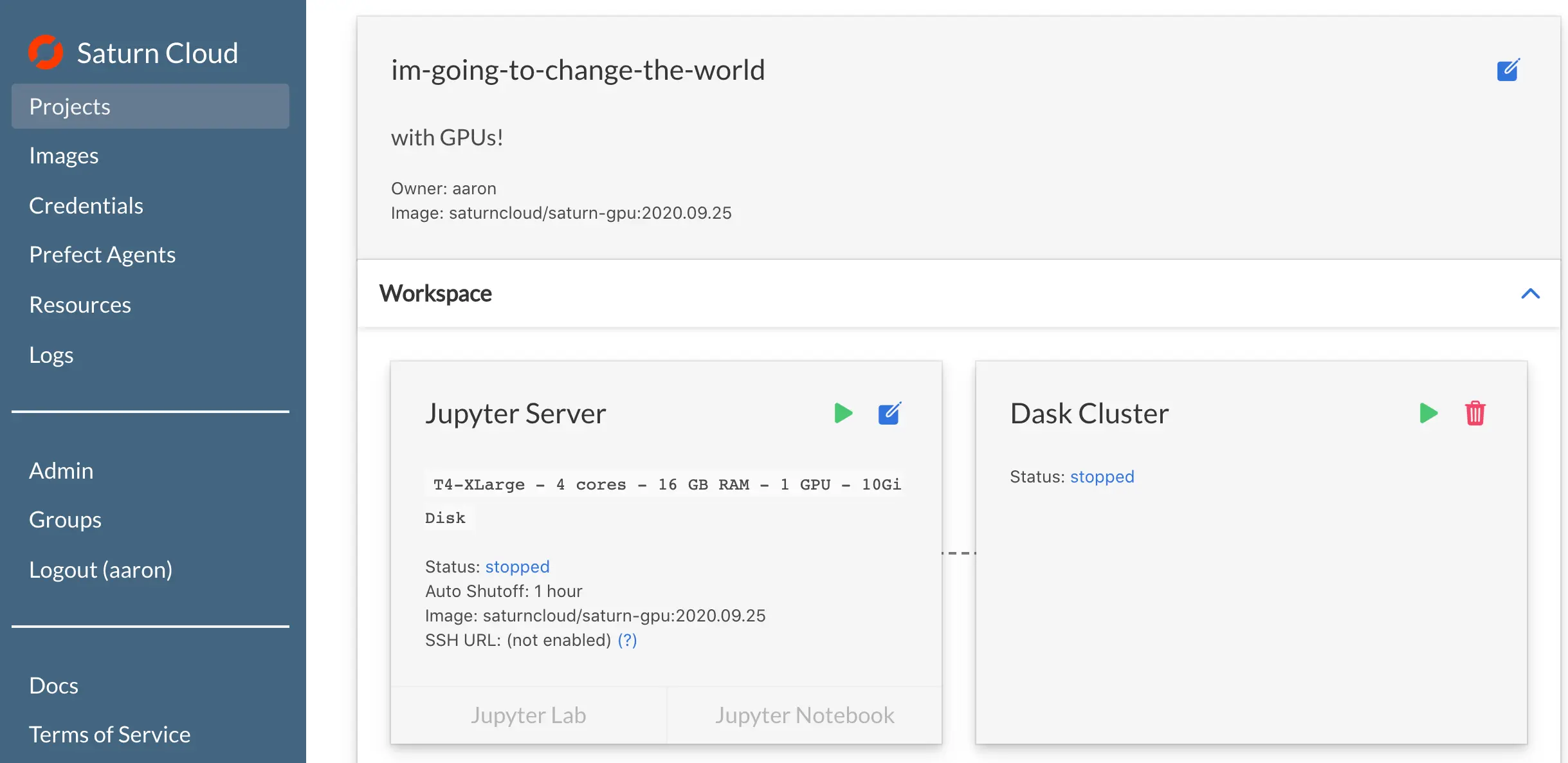
Change the world with GPUs on Saturn Cloud Hosted
The vision of Saturn Cloud Hosted with NVIDIA GPUs is to bring the world’s fastest data science and machine learning capabilities to everyone, regardless of budget, resources, and time. Whereas GPU-accelerated tooling was a luxury before, the dropping prices over time, plus cloud availability and infrastructure provided by Saturn Cloud make it a powerful tool for everyday users.
Faster random forest on GPUs
Let’s explore implementations of distributed random forest training on clusters of CPU machines using Apache Spark and compare that to the performance of training on clusters of GPU machines using RAPIDS and Dask.
You can read about this benchmark in more depth here. We trained a random forest model on 300,700,143 instances of NYC taxi data on Spark (CPU) and RAPIDS (GPU) clusters. Both clusters had 20 worker nodes and approximately the same hourly price. Here are the results for each portion of the workflow.
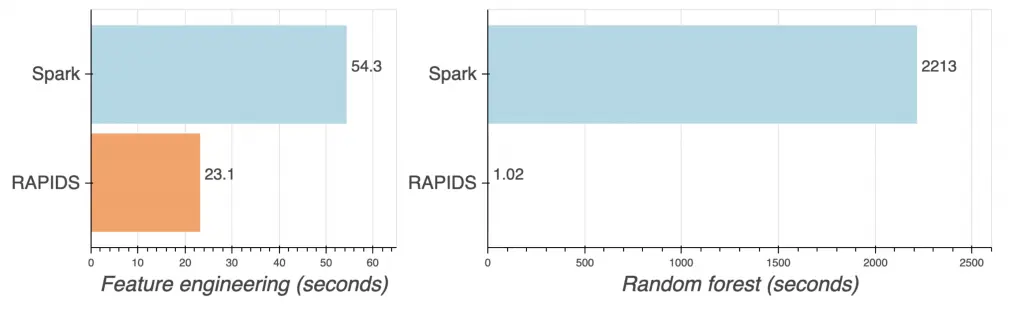
That’s 37 minutes with Spark vs. 1 second for RAPIDS!
GPUs crushed it — that’s why you’re going to be so thrilled to have them now. Think about how much faster you can iterate and improve your model when you don’t have to wait over 30 minutes for a single fit. Once you add in hyperparameter tuning or testing different models, each iteration can easily add up to hours or days.
Need to see it to believe it? You can find the notebooks here! Or continue reading to see how to set up a project in Saturn Cloud Hosted and run it for yourself.
Accelerating data science with GPUs on Saturn Cloud Hosted
It’s easy to get started with GPUs on Saturn Cloud Hosted, and we’ll walk through the above random forest model training exercise using a sample of the data. The example uses NYC Taxi data to train a random forest model that classifies rides into “high tip” or “low tip” rides. The notebooks come pre-loaded into a “RAPIDS” project when you create an account, or you can grab the notebooks yourself here.
We start by loading a CSV file into a dataframe, but since we’re using the RAPIDS cudf package, the dataframe gets loaded into GPU memory:
import cudf
import s3fs
s3 = s3fs.S3FileSystem(anon=True)
taxi = cudf.read_csv(
s3.open('s3://nyc-tlc/trip data/yellow_tripdata_2019-01.csv', mode='rb'),
parse_dates=['tpep_pickup_datetime', 'tpep_dropoff_datetime']
)
Then after some feature processing, we train our random forest model
from cuml.ensemble import RandomForestClassifier
# see notebook for prep_df function
taxi_train = prep_df(taxi)
rfc = RandomForestClassifier(n_estimators=100, max_depth=10, seed=42)
rfc.fit(taxi_train[features], taxi_train[y_col])
The great part about Saturn Cloud Hosted is that this code “just works”. The environment is set up for you, the GPU is hooked up properly, and now you can focus on training a model.
If your dataset is large, using a single GPU may not be enough, because the dataset and subsequent processing must fit into GPU memory. That’s where a Dask cluster on Saturn Cloud Hosted comes in! You can define a cluster from the UI or from within a notebook, making sure to choose a GPU size for the Dask workers:
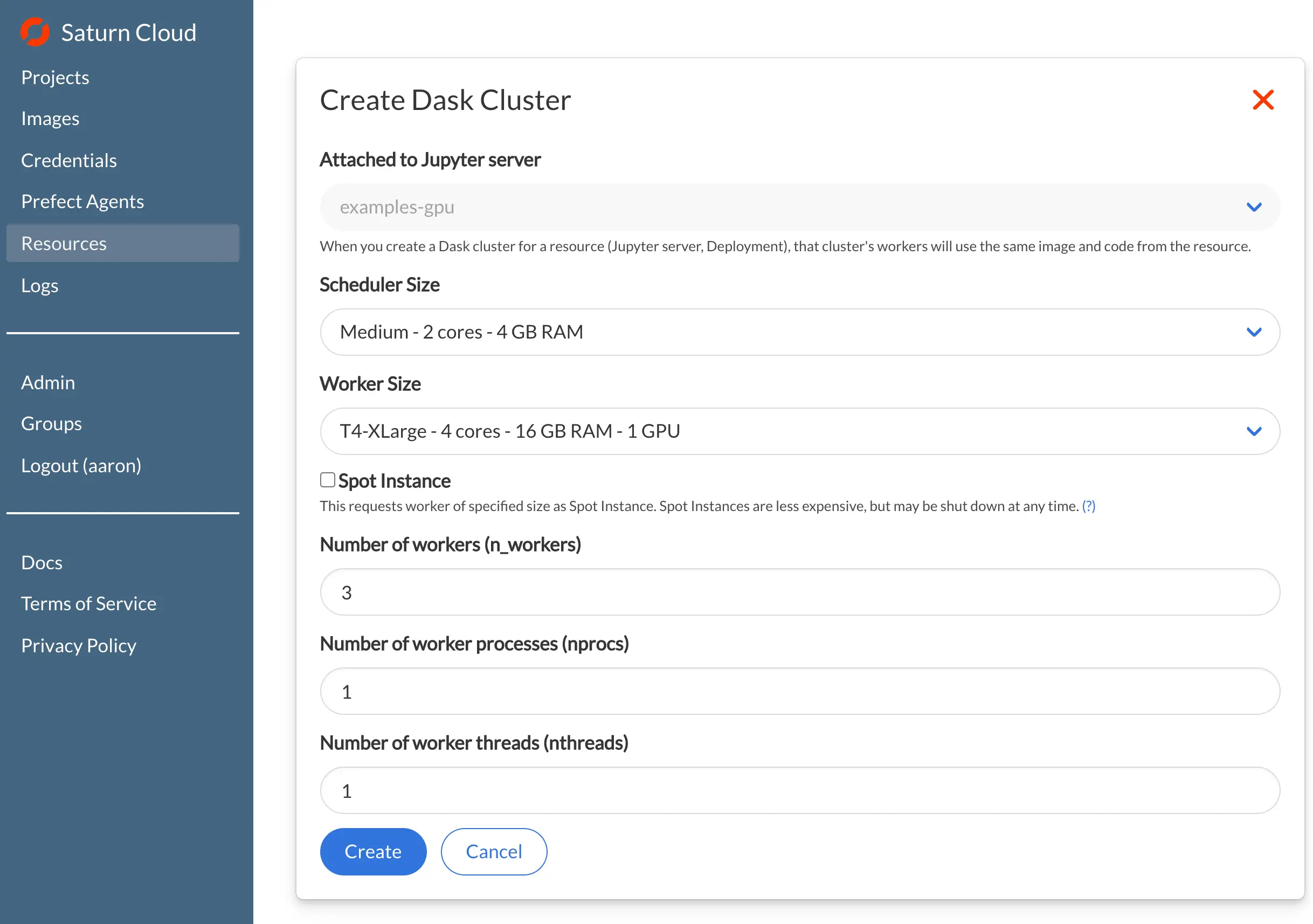
from dask.distributed import Client
from dask_saturn import SaturnCluster
cluster = SaturnCluster(
n_workers=3,
scheduler_size='medium',
worker_size='g4dnxlarge'
)
client = Client(cluster)
Then it’s a matter of importing the proper RAPIDS modules and sub-modules for distributed GPU processing:
# notice "dask" in these imports
import dask_cudf
from cuml.dask.ensemble import RandomForestClassifier
taxi = dask_cudf.read_csv(
's3://nyc-tlc/trip data/yellow_tripdata_2019-01.csv',
parse_dates=['tpep_pickup_datetime', 'tpep_dropoff_datetime'],
storage_options={'anon': True},
assume_missing=True,
)
taxi_train = prep_df(taxi)
rfc = RandomForestClassifier(n_estimators=100, max_depth=10, seed=42)
rfc.fit(taxi_train[features], taxi_train[y_col])
Do you want an easy way to get super-fast GPU data science?
Yes! You can get going on a GPU cluster in seconds with Saturn Cloud Hosted. Saturn Cloud handles all the tooling infrastructure, security, and deployment headaches to get you up and running with RAPIDS right away. Click here for a free trial of Saturn Cloud Hosted!
If you are part of a company that requires a virtual private cloud solution, Saturn Cloud also offers an Enterprise solution that you can find here.