
Introduction to Docker
In the rapidly evolving field of machine learning, one challenge consistently surfaces - reproducing environments for consistent model training and prediction. This is where Docker, an open-source platform, has proven transformative. Docker provides a streamlined process to “containerize” machine learning environments, eliminating the classic problem of inconsistent results due to varying dependencies, library versions, and system variables. Imagine creating a model that runs perfectly on your local machine, only not to behave as expected when deployed to other environments for testing or production. Docker powerfully addresses this frustrating “it works on my machine” through a concept called containerization.
In addition to consistency, Docker offers another substantial advantage - resource optimization. Traditional virtual environments run complete copies of an operating system for each application, leading to resource redundancy and inefficiency. Docker’s architecture, in contrast, allows for sharing system resources among multiple isolated containers, each running its application. This promotes efficiency and enables lightweight, scalable deployment of machine learning models, a quality essential in the big data era. Thus, Docker is not just a tool; it’s a game changer for machine learning processes, promising portability and efficiency.
What are Docker containers?
As aforementioned, Docker cooperates directly with the host machine’s kernel, allowing multiple containers to simultaneously and dynamically share resources when needed. By doing so, Docker drastically reduces the overhead costs of virtualizing an entire OS and focuses on only the application’s needs.
Additionally, Docker can adeptly manage and allocate system and GPU resources among containers, utilizing Linux kernel features like control groups (or ‘cgroups’). Cgroups are pivotal to efficiently managing resources, preventing any single process from hogging shared resources and ensuring fair usage. Docker guarantees that each application doesn’t cross a defined limit and receives the necessary resources, maximizing efficiency and providing isolated environments for each process. Docker plays a crucial role as a resource manager in this aspect, effectively applying cgroups to control and isolate resource usage. As a result, Docker containers emerge as the optimum solution for running GPU-intensive tasks, offering a perfect blend of portability and high resource efficiency for applications that contain machine learning models and heavy data computation.
Why use Docker containers for machine learning?
Leveraging Docker containers for machine learning unpacks many more beneficial use cases than portability. In addition to easy and reproducible application deployment across varying environments, Docker enables effective parallelization and redundancy for your workloads. This ability to distribute tasks across multiple systems is instrumental during the model training process and also in maintaining robust deployments.
With Docker containers, you gain the benefits of:
- Portability and Parallelization: DDocker containers encapsulate applications and their dependencies, enabling them to run independently across diverse environments. This trait extends to facilitate parallel execution of workloads on multiple systems. This can significantly accelerate computations during model training and contribute to redundancies in deployment. If one system faces an outage, the distributed nature of the containers ensures that deployments can promptly restart on other operational systems.
- Isolation: Docker containers operate in isolation from the host system and other containers. This ensures each application enjoys a conflict-free, consistent execution environment.
- Scalability: Containers, owing to their lightweight nature, can easily be scaled to match the volume and complexity of your machine learning workload. This provides a mechanism for optimized resource utilization, which is especially critical when handling large datasets or complex models.
- Resource Allocation: Docker’s in-built support for NVIDIA GPUs enables allocating specific GPU resources to each container. This proves beneficial when single-machine resources are insufficient due to competing demands or large application sizes. With Docker, containers can be distributed across systems, utilizing their collective resources, including GPUs.
Numerous tools have embraced Docker’s containerization to streamline and enhance their performance. Notably, Metaflow, a framework designed for building and managing real-life data science projects, leverages Docker containers to effectively simplify the orchestration of complex machine learning workflows. Its ability to encapsulate and manage machine learning experiments within Docker containers offers a structured and reproducible approach to data science projects, facilitating collaboration and ensuring consistency across experiments. Metaflow is able to create a central platform for data science teams to view experiments and reproduce the environments easily across any team member’s machine.
Another prominent tool is Kubeflow, an open-source platform designed to streamline and automate the deployment, management, and orchestration of machine learning workflows on Kubernetes. Kubeflow can parallelize various aspects of machine learning workflows, including distributed training of models, parallel data preprocessing, and concurrent execution of multiple machine learning experiments, allowing for efficient utilization of computing resources and faster experimentation.
These tools can vastly speed up various machine learning pipeline stages by leveraging efficient resource utilization and parallel processing capabilities of containerization and GPUs. This ranges from data ingestion and model training to validation and deployment, paving the way for quicker iterations and, consequently, faster delivery of high-performing machine learning models.
Installing Docker with GPU Support
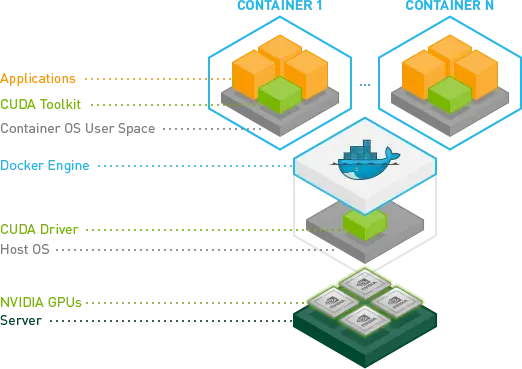
To unlock the vast potential of GPUs in a Docker-operated environment, you require a specialized toolkit: the NVIDIA Container Toolkit. This toolkit powers GPU-accelerated applications within Docker containers through various mechanisms such as GPU isolation, ensuring driver compatibility, and providing access to crucial GPU libraries. Furthermore, the NVIDIA Container Toolkit integrates seamlessly with prominent container runtimes, including Docker.
Furthermore, the NVIDIA Container Toolkit simplifies the otherwise complex GPU resource management, provides ready-to-use container images pre-configured with deep learning frameworks, and ensures harmonious operation between NVIDIA drivers, CUDA versions, and container runtimes. This harmony establishes an efficient, containerized setting for developers and data scientists to run GPU-accelerated tasks. To utilize GPU capabilities within Docker, please follow the given steps.
Step 1: Install NVIDIA drivers
Before installing the NVIDIA Container Toolkit, you must install the NVIDIA drivers on your host system. NVIDIA drivers provide the interface between the physical GPU and the operating system. To install NVIDIA drivers, you can follow this link here.
However, from our experience, the quickest and easiest way to install NVIDIA drivers is via the CUDA installation path, as NVIDIA’s drivers are installed as a dependency in this installation. For a more straightforward installation by simply installing CUDA, follow this link and use the “deb (network)” option for your installation method. Doing so will also allow you to stay updated with the latest drivers and CUDA versions from NVIDIA’s official repositories.
Step 2: Install Docker
Install Docker on your host system.
- If you want the Docker GUI (Docker Desktop) with the Docker Engine, click here.
If you only want the Docker engine, click here.
Step 3: Install NVIDIA Container Toolkit
Depending on the package manager provided by your operating system, follow this guide’s “Installation” section and use the corresponding terminal commands to install the toolkit.
After following the “Installation” section, continue with “Configuration” to allow Docker to the NVIDIA container runtime by default. This benefits the docker build process, which will be mentioned in more detail later in this article.
Step 4: Add User to docker Group
Finally, add the user to the docker group, allowing the user to use docker without sudo. This will enable the user to pull images and create containers. The steps for this are found here.
Passing in a GPU into a Docker Container
Once you finish the installation steps above, it’s time to verify that your Docker container has access to the GPU.
Step 5: Verify GPU Usage Inside Docker
To verify, run the following command:
docker run --gpus all nvidia/cuda:11.0-base nvidia-smi
This command runs a Docker container with access to all GPUs and runs the nvidia-smi command, which displays information about the GPUs. If the command displays information about your GPU, then your Docker container has access to the GPU.
Step 6: Use GPU from your Docker container
When initializing a Docker container, specify the --gpus option when running your container. For example, to run a TensorFlow container with GPU support, run the following command:
docker run --gpus all tensorflow/tensorflow:latest-gpu
This command runs a TensorFlow container with access to all GPUs. If your system has multiple GPUs and you would like to specify only one or several of them to be visible to the container, use nvidia-smi to identify the GPU device number and pass them in a comma-separated list, as shown below:
docker run -it --rm --gpus '"device=0,2"' tensorflow/tensorflow:latest-gpu nvidia-smi
For more information on passing in GPU device IDs and other docker run parameters, click here.
Utilizing a GPU during docker build
In certain scenarios, you might want to engage your NVIDIA GPU during the docker build process. This could involve compiling CUDA code into an executable or pre-computing certain values using the GPU to be built into the Docker image. Another reason to use your GPU during docker build could be for preliminary tests during the image build process to see if your application runs correctly on the GPU. To enable the GPU during the image build process, you must set your Docker’s default runtime to nvidia in the daemon.json file and restart the Docker service. Please follow these steps:
- Open
daemon.jsonfile
a. Locate and open the daemon.json file in a text editor. This file resides in the /etc/docker/ directory.
- Set
default-runtimetonvidiaand save the file.
a. In the daemon.json file, add the nvidia runtime and modify the line “default-runtime”: “nvidia”. If no such file exists or it’s empty, you can create it with the following content:
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
}
- Restart the
dockerservice by typing insudo systemctl restart docker.
Now, your GPU will be accessible during the Docker build process. Note that this defaults all new containers to use the NVIDIA runtime, but this should not cause any issues with your current containers. If you want to launch containers without accessing the NVIDIA runtime, you’ll have to specify it when running the container using the --runtime flag (for example: docker run --runtime=runc …).
NVIDIA GPU Cloud (NGC)
Although the name suggests cloud usage, NGC is a platform and registry provided by NVIDIA that offers a repository of pre-built and optimized container images, software, and deep learning frameworks for use with NVIDIA GPUs on any system. NGC provides a convenient way for developers and data scientists to access containerized and secure software stacks already configured to work seamlessly with NVIDIA GPUs. These containers include popular deep learning frameworks like TensorFlow, PyTorch, and others, as well as libraries, tools, and GPU-optimized drivers. Users can pull these containers from NGC and run them on their GPU-equipped systems, saving time and effort in setting up and configuring GPU-accelerated environments.
For instance, NGC images can help create separate containers with different CUDA, cuDNN, and TensorRT versions, making isolated environments more consistent and error-prone. NGC containers can also be used as base images with docker build to create applications on top of them, all without installing additional NVIDIA libraries on your system.
To view NVIDIA’s selection of images to choose from, click here.
Conclusion
Harnessing the computational prowess of GPUs from a Docker container offers a flexible, scalable, and powerful solution for executing machine learning tasks. This blog post has guided you through enabling your Docker containers to utilize GPUs, paving the way for accelerated machine learning workflows.
The advantage here isn’t just about speed but also operational efficiency and resource optimization. Whether you’re orchestrating complex machine learning computations in the cloud or managing shared infrastructure resources, Docker’s scalability and GPUs' raw power conclusively simplify the task of building and deploying intricate machine learning models. Understanding and implementing these insights will remain critical as the world’s demand for compute rapidly increases.
Docker’s impressive blend of flexibility and power, in conjunction with the high-performance computing potential of GPUs, truly equips us for the future of machine learning experimentation and deployment.
Resources
- Random Forest on GPUs: 2000x Faster than Apache Spark
- Speeding up Neural Network Training With Multiple GPUs and Dask
- Multi-GPU TensorFlow on Saturn Cloud
- My First Experience Using RAPIDS
- Use R and Torch on a GPU
- Introduction to GPUs
- Top 10 GPU Computing Platforms
- Train a TensorFlow Model (Multi-GPU)
- Use RAPIDS on a GPU Cluster


