
Introduction
Documents sometimes are distributed under scanned versions and usually combined together into one merge doc. To retrieve the specific document, the user needs to locate the required document inside the concatenated PDF file, and it is not an easy task. The concatenation contains at least more than a hundred pages of documents, and they have a different structure or number of pages in each document.
To un-concatenated complex documents is still a challenging topic, there are multiple reasons behind this that the concatenated documents contain multiple documents, and each of these documents may be multi-themed and different in document length, and structure. For example, the business document can have five pages with business information, structure, product or service, or the policy document may contain one page of police definition. As a result, the document length and index information are not provided, so this problem has drawn attention to the document classification task in which users may need to index different types of policy documents, precisely, given a scanned document which contains various types of sub-documents.
This blog aims to introduce a method to automatically identify the index, each document structure and un-concatenate separate documents based on the Natural Language Processing and Computer Vision model. Our target model will be a combination of BERT and VGG16 for Language and Vision analysis, respectively.
Methodology
There are three main parts to experimenting with this research. The first part is to convert the PDF file into Image format in which each image corresponds to each page of the original PDF file. The next step is to generate the feature from Doc2Vec and TF-IDF function. The final step is training the classification model to classify every single image corresponding to a page of the original document and assign the label for them. Based on the predicted class, we can find the starting indexes of sub-documents.
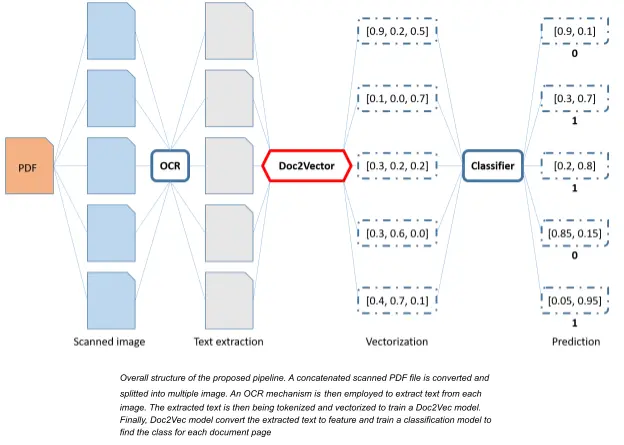
PDF2Image
As the PDF files in the provided data set have different numbers of pages, different types of documents and different layouts, we have to convert them into images for easy manipulation and processing. In this step, we have many libraries to choose and convert the pdf files to images. We tried pdf2image and pypdfium2, each library has its own advantages and disadvantages. In the end, we decided to employ the pypdfium2 library to convert each scanned document into a set of images where each image is a page in the original document.
The function is quite straightforward as shown below:
import tqdm
import pypdfium2 as pdfium
def extract_images(f): # f is the path to the pdf file
for (image, suffix) in pdfium.render_pdf_topil(f):
# filename is the path to save each image
image.save(filename)
Data Preprocessing
Label Converter
Every image is saved to the appropriate folder for future learning process using the label provided in the dataset along with the PDF files. The label is annotated using the gold standard in json format as shown below:
{
"893872": [1, 168, 13, 1, 12, 2, 3, 26, 1, 6],
"890952": [151],
...
}
where keys and values are PDF names and number of pages of each sub-document in the corresponding PDF file, respectively. In the example above, the PDF file 893872.pdf has 10 sub-documents which have 1, 168, 13, 1, 12, 3, 26, 1, 6 pages, respectively. We label the starting page as 1.0 and the others as 0.0(s) so we convert the gold standard labels to one-hot-like labels. Specifically, given a gold label [2, 5, 3, 4], the converted label is: [1,0,1,0,0,0,0,1,0,0,1,0,0,0], as shown on the following figure.
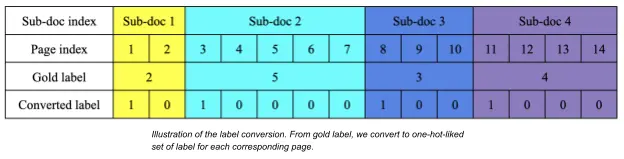
The converting program is shown below:
import numpy as np
def gold_to_onehot(original_indexes):
onehot = np.array([])
for i in original_indexes:
temp = np.concatenate((np.ones((1)),
np.zeros((i-1))))
onehot = np.concatenate((onehot, temp))
return list(onehot)
Tokenization
Once the text is extracted from the images using OCR, they need to be tokenized. Tokenization is the process of breaking the raw text into small chunks which can be words, phrases or sentences called tokens. These tokens help in understanding the context or developing the model for the NLP. The tokenization helps in interpreting the meaning of the text by analyzing the sequence of the words.
The most basic way to tokenize a text is to split it using special characters such as space, comma or dot. In this work, we employ a more sophisticated library called Natural Language Toolkit (nltk) for the tokenization task, as shown below:
import nltk
def tokenize_text(text):
tokens = []
for sent in nltk.sent_tokenize(text):
for word in nltk.word_tokenize(sent):
if len(word) < 2:
continue
tokens.append(word.lower())
return tokens
Vectorization
Now we have the text and the extracted tokens. However, a machine learning model doesn’t use text or tokens to train itself but the vectors, so we have to transform the extracted text to a set of vectors for training and for inference. Gensim is a library that helps vectorizing text in NLP problems. Having a corpus which is our extracted text, we first do some preprocessing to get rid of all punctuation marks as shown in function cleanText. Gensim will take the cleaned text and train a Doc2Vec model. The basic idea is: act as if a document has another floating word-like vector, which contributes to all training predictions, and is updated like other word-vectors, but we will call it a doc-vector. Gensim’s Doc2Vec class implements this algorithm.
from bs4 import BeautifulSoup as BS
def cleanText(text):
text = BS(text, "html.parser").text
text = re.sub(r'\|\|\|', r' ', text)
text = re.sub(r'\\n', r' ', text)
text = re.sub(r'http\S+', r'<URL>', text)
text = text.lower()
text = text.replace('x', '')
return text
Training
In this section, we describe the process of training the fused model which is a combination of the CNNs vs a Natural Language Processing (NLP) (BERT). Having the vectorized data, we are ready for the model. We consider this document splitting challenge as a binary classification problem where we define the starting page of each sub-document as label 1 while others pages are label 0. We first split the dataset into 3 parts (training part, validation part, and testing part) using the train_test_split function from Sklearn with the ratio of 70:15:15 using stradify strategy on the labels. The train_test_split function will divide the training set into 3 parts based on the number of labels to make them equally distributed among parts. We design the VGG-BERT model which consists of a vision branch with a BERT as shown below.
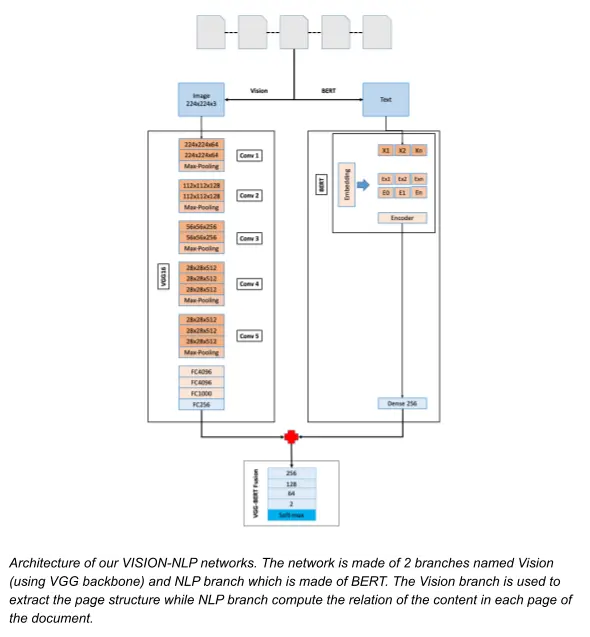
We design a fused-model which consists of two branches: one branch is built using Convolutional Neural Networks (CNNs) to extract the image structure and the other is built for the Natural Language Processing task to understand the content of every page. For the CNN part, we start with the VGG16 and test with other backbone such as ResNet34, ResNet50, and finally EfficientNet family. On the other hand, we employ BERT English and BERT Dutch, which were built on English and Dutch corpus, respectively.
Vision branch
For this branch, we have multiple choices starting from the old VGG16 model to the most recent EfficientNet (B0 - B7). The model takes an input image of 224×224×3 and passes through an extractor to generate an image feature which is expected to be merged with the NLP feature from the other branch. Due to resulting use for fuses with LSTM and BERT branch, we have disconnected the soft-max layer as we need the embedding to be passed to a dedicated Multi-Layer Perception (MLP) for the binary classification task in the combination sequential phase of the model. A fully-connected layer of 256 units is added on top of the network with 0.3 dropout regularization. We did a few experiments, and decided to go with VGG16 because of its simplicity and performance compared with other backbones.
VGG16 is a convolutional neural network that is 16 layers deep. We employ the pre-trained weights of the network trained on more than a million images from the ImageNet database. The pre-trained network can classify images into 1000 object categories, such as keyboard, mouse, pencil, and many animals. Input image of 224×224×3 passes through the first convolution block which has two convolution layers, 64 convolution filters, measuring 3×3, were then used across the input image to extract 224×224×64 feature map data. ReLU activation function was used in converting negative values to 0. Max-pooling process 2×2 for downsize of first feature map to 112×112×64. In the second convolution block, the same convolution layer keeps the first two dimensions of the previous layer and increases the third dimension from 2-times to 128. Max-pooling was used to reduce the dimension to 56×56×128. The process was repeated thrice to reach the fully connected block with adding one more convolution layer for the last-two convolution blocks.
NLP branch
This branch is responsible for extracting the content feature of each page in the document. There are various techniques for this specific task which consider the text data as a data sequence that has meaning, including Long short-term memory (LSTM) unit or the most recent technique named Transformer (BERT). BERT is the new state-of-the-art model based on Attention mechanism and Transformer for various NLP tasks. BERT is ready to be fine-tuned by adding a single layer at the output layer. There are two pre-trained versions of the model: Bert-base and Bert-large. The difference between base and large is the number of encoder layers. Bert-base and Bert-large have 768 and 1024 hidden layers corresponding. In this project, to minimize parameters, we decided to use the pre-trained Bert-base model, Bert-base is pre-trained from unannotated data from the 800M words from books corpus and 2500M words from English. The model takes input with string format and returns an output tensor with shape of 1×768. The sub-layer with 256 units is added at the output layer to transform for the fusion sequential phase. We tried two versions of BERT named BERT and BERTje which were trained on two corpus English and Dutch, respectively.
Fusion branch and MLP
We have adopted the Fusion approach of combining the image and text features coming from VISION and BERT branches. The feature vector dimension of the vision-branch is 1×256, NLP branch is 2×128 for bi-direction (forward and backward) and BERT is 1×256. To perform fusion-branch, output of bi-direction NLP branch was merged into one dimension with shape 1×256. We concatenated the feature vector (VISION-BERT) and passed the fused-feature vector into a three layered MLP with 256 units of input, 128 units of hidden and 64 units of output layer. The final output layer is the soft-max activation. Each layer has a dropout of 0.6. Batch size has been fixed 128 with Sharpness-Aware Minimization(SAM) optimizer function. The loss function is Focal Loss be used as an alternative for cross-entropy loss with imbalanced datasets. Learning rate has been set initially at 0.001 with cosine annealing scheduler.
Evaluation
To quantify the model performance in the classification task, all models were tested on validation and testing dataset. The validation dataset is extracted directly from the training dataset, so we evaluated it using four criteria: sensitivity, specificity, mean accuracy and f1-score. Sensitivity refers to the probability of a positive test, conditioned on truly being positive. Specificity refers to the probability of a negative test, conditioned on truly being negative. Mean accuracy indicates the average percentage of correct prediction for each class. F1-score also known as balanced F-score, indicating perfect precision and recall, combine precision and recall into one metric by taking their harmonic mean. Those four criteria are calculated as shown below:
Bcubed precision and recall is calculated based on clusters as illustrated on the figure below. The precision and recall for each entity are calculated and then combined to produce the final precision and recall for the entire output.
recalli=correct_elements/true_elements
precisioni=correct_elements/ouput_elements
where correct_elements, true_elements, and output_elements are the number of correct elements in the output chain containing entity i, number of elements in the true chain containing entity i, and number of elements in the output chain containing entity i, respectively.

precision=(TP+TN)/(TP+FN+TN+FP)
F1_score=2*precision*recall/(precision + recall)
where *TP, TN, FP, FN* are True Positive, True Negative, False Positive, and False Negative, respectively.
Evaluation on the validation dataset
We designed experiments that assess the impact of training data size on the VGG-BERT model. The training data percentage increases from 25% to 100% with a step size of 25% and reports their accuracy, and F1-score. The validation dataset includes 30% of the all dataset, splitted randomly at random state 42 without any augmentation. We also compare four above-mentioned metrics, as shown on Table\ref{tab:table1}. As we can see, VGG16-BERT reaches 70.41% in sensitivity, 98.28% in specificity, 93.40% in accuracy and 78.87% in F1-score.
Effect of training data size: The results show that all models are sensitive to training data size, as the accuracy changes significantly after increasing training data. VGG-BERT produced accuracy increase from 86.70% to 92.20%, 92.22% and 93.40%
On the other hand, in terms of Bcubed VGG-BERT produces accuracy that increases from 93.61% to 93.97%, 95.74% and 97.22%.
Conclusion
We built an efficient document splitting using a combined model which consists of a Vision branch (VGG) and language branch (BERT). By cooperating with the vision feature and language feature, the proposed model successfully classifies the starting page and non-starting page. As a result, it helps identify the start-page for each sub-document in concatenated one.
Final Thoughts and Future Work
The most obvious way to improve this model is to plug-and-play with more powerful vision branches and/or language branches. For example, VGG16 is quite old yet a good baseline, there should be other models like EfficientNet, ResNet or even Transformer. Furthermore, with the development of recent language techniques, language models are also developed and become more efficient and powerful. Author will leave this as a future work for the incoming articles.
You may also be interested in:


