
This article was published when data science tooling like Dask and R was a primary focus for Saturn Cloud. Today, Saturn Cloud is the enterprise AI platform for any GPU infrastructure.
Prefect is a data pipeline automation tool based on a simple premise: “Your code probably works. But sometimes it doesn’t.” If you check the Prefect documentation, you will find the terms positive data engineer and negative data engineering have been often mentioned to describe what Prefect is for. To understand Prefect, let us first understand what each of these terms means.
Positive Data Engineering : Writing your code and expecting it to run successfully.
Negative Data Engineering : Writing your code in a defensive way so that it can handle failures .
Prefect helps you manage negative engineering situations in your data science project. In an ideal world you write code, it runs smoothly and you achieve your targeted objective. In the real world your nicely written code may encounter multiple unexpected issues. Prefect helps with these unexpected realities.
What is Prefect?
Prefect is a Python-based workflow management system which helps in building, running and monitoring millions of data workflow and pipelines. It helps in improving behavior of your workflows and handling missing engineering. This means that Prefect will ensure that either your code is successfully executed or if things go south it fails successfully. Let’s understand this with an example. Say our goal is to clean ticket price data for a Railway System. A simple workflow might be:
fetch data -> extract columns -> create new features -> handle noise -> save
This workflow looks fine, but only if things don’t go wrong. What happens when fetching data fails or there is an unexpected issue while creating new features? This is where the Prefect pipeline automation comes into use. Prefect makes it easy to add safety checks to your workflow to handle these sorts of behavior, thus improving its overall behavior. You’ll no longer have situations where an error in your code causes the pipeline to fail and you discover cascading bad effects (or worse, there are cascading effects and you don’t notice them).
Prefect is easy It is written in Python. So if you know how to write your functions utilizing standard interfaces of python, writing it around prefect components is easy.
Action time: working through the example
Let us look at an example and see how with few changes to your existing code, you can improve behavior of your workflows:
Objective: I have taken Spanish train data from Kaggle. I have two objectives here:
- Predict the prices of train tickets.
- Get a ticket price as parameter and check whether it is high priced or low priced compared to the predicted test set.
The Kaggle Spanish trains dataset has a row for each origin/destination pair of routes within Spain. Below are the first few rows of the data. Each row has information on route, price, train type, travel duration and seat availability.

We are performing following functions:
Reading file and filtering out rows where price of ticket is not given
Extracting predictors and doing one hot encoding
Extracting target variable
Performing linear regression to predict ticket price
Now lets explore the prefect features included in code below.
Task: Task can be conceptualized as a function–it’s a standalone chunk of work to be done. This chunk of work might accept inputs and it might produce outputs. Notice for each of the tasks I am performing, I have used task decorator
Handling Failure: For handling the missing engineering or what ifs, we have used a simple measures here. max_retries and retry_delay. Let’s say for example you workflow is not able to retrieve data from data source. In our case data source is from local, but in real life data source can be
realtime streaming or stored in cloud. We can utilize Prefect task’s retry feature In code above for task get_data, max_retries will ensure that data loading is retried up to given n number of times and retry_delay will keep waiting time to 10 seconds between each retry.
@task
def get_data(max_retries=3, retry_delay=timedelta(seconds=10)):
spain=pd.read_csv("train.csv")
df=spain[spain['price'].notnull()]
return df
@task
def dummies(spain):
X=spain[['origin','destination','duration']]
X=pd.get_dummies(X, columns=['origin','destination'])
return X
@task
def target(spain):
y=spain['price']
return y
@task
def pred(X,y):
x_train,x_test,y_train,y_test=train_test_split(X,y,test_size=0.2)
lr = LinearRegression(fit_intercept = True, normalize = False)
lr.fit(x_train,y_train)
return lr.predict(x_test)
Again for code below, we are using task decorator . Function check_ticketPrice is sending back a boolean value. If the parameter u has value less than the mean predicted price for train ticket, the returned value will be true.
In the next three functions we are printing type of fare as per the returned boolean value:
@task
def check_ticketPrice(p,u):
return u < p.mean()
@task
def action_if_true():
return "Low Fare!"
@task
def action_if_false():
return "High Fare!"
@task(log_stdout=True)
def print_result(val):
print(val)
Now let’s check next piece of code. The following Prefect concepts will come up:
Flow: A “flow” is a container for multiple tasks which understands the relationship between those tasks. In our example above while creating a Prefect flow, we are creating an order in which we want our tasks to run. Tasks are arranged in a directed acyclic graph (DAG), which just means that there is always a notion of which tasks depend on which other tasks, and those dependencies are never circular.
With Case: Cases are used when you want to create conditional workflows. These are very useful in handling different outputs and managing errors in workflow. In our example we are handling two use cases. First when action is true and second when action is false. Once we have handled both cases we are merging both together in our flow with merge functionality.
Parameters : Parameters enable users to send inputs when flow is running. Here we have declared a parameter named ticket_price for price of a ticket and we are passing this parameter into the function check_ticketPrice.
with Flow("Run Me") as flow:
param_p = Parameter(name='ticket_price', required=True)
e = get_data()
X=dummies(e)
y=target(e)
#prediction
p=pred(X,y)
cond = check_ticketPrice(p,u=param_p)
#with case
with case(cond, True):
t = action_if_true()
with case(cond, False):
f = action_if_false()
val = merge(t, f)
print_result(val)
The directed acyclic graph which is made by flows can be viewed by flow.visualize(). The nodes represent task names and edges represent the data being passed. In graph below you can see that some of the tasks are carried in parallel . In our example tasks labelled target and dummies both have the same dependency (The DataFrame spain), hence are being carried out in parallel.
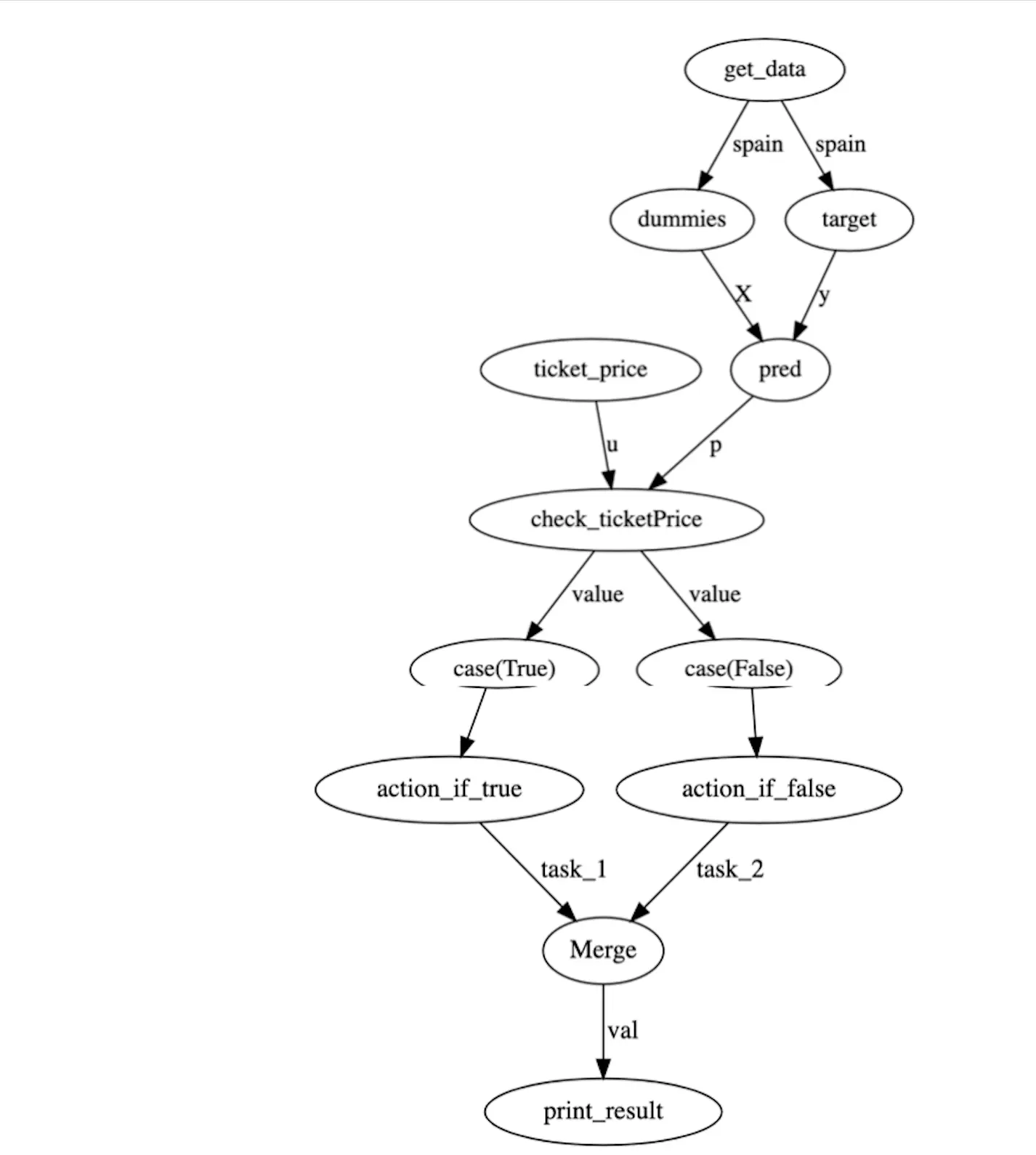
Now we can run the flow created above with flow.run(). In our run function we will have parameter set to the value we want to pass . In code below I am passing value 20 as price
of a ticket. Notice that argument is passed as dictionary , where parameter name ticket_price is the key and 20 is the value. Here we have set default value for parameter. You can also set parameters at flow ->run. See the prefect docs for more details.
flow.run(parameters={'ticket_price': 20})
Using Saturn Cloud with Prefect
Saturn Cloud is set up to easily run and automate Prefect workflows. Saturn Cloud has support for Prefect so it can be the computation environment for the Prefect tasks. Hence when you want to use Prefect you don’t have to configure and host it yourself.
Saturn cloud also supports Prefect Cloud, which is a hosted, high-availability, fault-tolerant service that handles all the orchestration responsibilities for running data pipelines. In this setup Prefect Cloud hosts the orchestration of the tasks while Saturn Cloud runs the actual tasks themselves.
The following are some of the features for Using Saturn Cloud and Prefect Cloud together:
- Configuring Prefect Agent : Creating Prefect Cloud Agent in Saturn Cloud in easy. Saturn Cloud is doing all heavy lifting in background and you need to do just few clicks to get it up and running.
- prefect-saturn : This Python package makes it easy to run Prefect Cloud flows on a single machine with Saturn Cloud.
prefect-saturnadds storage, run config, executor and labels to your flow by default. - Data/ Code : All of your sensitive data, code and credentials stay within Saturn Cloud. Prefect Cloud only gets a minimal description of the flow without any sensitive information.
- Logs : You can view logs of your flows in Saturn Cloud UI. Logs and task statuses are sent to back to Prefect Cloud, in case you need to review those.
- Environment : Saturn Cloud lets you take advantage of adding GPU to your code and lets you choose the size of execution environment.
For more features and advanced tutorials check out the Prefect Docs and the Saturn Cloud docs
Image credit: Maxim Melnikov


