
Source: Freesoundslibraries
ChatGPT became one of the most popular NLP products between December 2022 and February 2023, adding about 100 million users globally and generating 1 billion monthly visitors. That explosion was partly caused by its conversational interface, which appeals to many people with varied levels of AI competence. It is simple to use, improves most people’s productivity, and embodies everything that makes a great product.
In case you missed it—ChatGPT is a conversational AI product powered by state-of-the-art large language models (LLMs) that have revolutionized the field of natural language processing (NLP). It can generate “human-like” text responses to various conversational inputs. It is trained on massive amounts of text data from different fields using unsupervised learning techniques, making it a powerful tool for a wide range of natural language processing applications.
It is a large language model (LLM) and, as such, has enormous capabilities, but when it needs to be used for specific domain areas (like healthcare), it might “hallucinate” and make false claims that aren’t based on the data it was trained on. As a result, depending on the use case, it needs to be fine-tuned for better results.
In this article, you will:
Get a general overview of transfer learning and fine-tuning in natural language processing.
Understand the effect of transfer learning and fine-tuning on ChatGPT’s conversational performance.
Learn about other techniques used in improving the performance of LLMs with focus on their advantages and disadvantages compared to transfer learning and fine-tuning.
An overview of transfer learning and fine-tuning in NLP
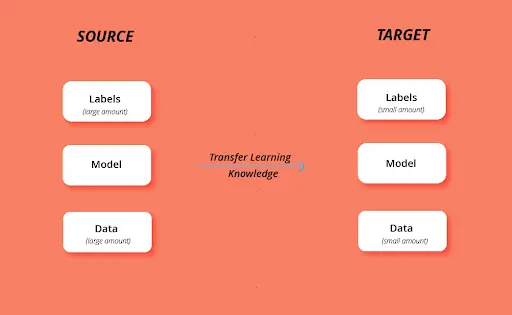
Transfer learning and fine-tuning are two key techniques used in natural language processing to enhance the performance of pre-trained language models.
In transfer learning, a pre-trained language model is applied to a new task or domain. At the same time, fine-tuning involves training the weights of the pre-trained model on a specific task or dataset to get optimal model performance.
These techniques are not new to NLP and are particularly useful for improving the performance of NLP models, which benefit greatly from the pre-existing weights (knowledge) encoded in pre-trained language models.
By utilizing transfer learning and fine-tuning ChatGPT on specific tasks or datasets, it can improve its performance significantly. This improvement can have positive implications for various industries, such as customer service, healthcare, education, and others. Those are use cases where conversational AI models like ChatGPT can be used to provide personalized and efficient user interactions.
Transfer Learning and Fine-tuning for Improved ChatGPT Performance
By utilizing the pre-existing knowledge of the pre-trained model, transfer learning enables you to create high-performing models with relatively little training data. In contrast, fine-tuning enables the model to learn a particular dataset.
Your dataset may not be enough to train a model from scratch, but by starting with a pre-trained model and tuning its parameters to better fit your specific task, you can fine-tune the model to improve performance.
The Dataset
To understand ChatGPT, you need to know that the dataset used to train and test the LLMs powering its conversational AI capabilities is publicly available. These LLMs are trained on massive text data, typically from sources like CommonCrawl, Wikipedia, corpora of books, and other publicly available text sources.
The training dataset is typically preprocessed to remove irrelevant or duplicate content and then used to train the large model using the Reinforcement Learning from Human Feedback (RLHF) technique. The testing dataset is typically used to evaluate the performance of the model on specific tasks, such as generating responses to user queries or engaging in multi-turn conversations.
Transfer Learning and Fine-tuning Process
The transfer learning and fine-tuning process applied to ChatGPT simply involves adapting the pre-trained “GPT-3 or GPT- 4” model to your specific domains or tasks. You typically achieve this by fine-tuning the model on a smaller dataset specific to the new domain.
This enables the model to learn task-specific features and further optimize its performance on the dataset. Find an example below with hypothetical data using Python and the Hugging Face Transformers library to make the concepts easy to understand.
Step 1:
Import the necessary libraries needed for your task.
# Import necessary libraries
import openai
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from transformers import GPT3Tokenizer, GPT3ForSequenceClassification, AdamW
Step 2:
Set up your Open AI API credentials, then load and preprocess your data. In this case, we used hypothetical healthcare data.
# Set up OpenAI API credentials
openai.api_key = "YOUR_API_KEY"
# Load and preprocess the healthcare dataset
df = pd.read_csv("healthcare_data.csv")
df = df.dropna().reset_index(drop=True)
df['label'] = np.where(df['class'] == 'positive', 1, 0)
texts = df['text'].tolist()
labels = df['label'].tolist()
# Split the data into training and validation sets
train_texts = texts[:800]
train_labels = labels[:800]
val_texts = texts[800:]
val_labels = labels[800:]
Step 3:
Load and initialize the pre-trained GPT3Tokenizer using the Hugging Face Transformers library, define the transfer learning architecture, and configure it for the task. You are looking at a GPT3 model for a classification use case like sentiment analysis, topic classification, answering questions, e.t.c.
# Load the GPT-3 tokenizer
tokenizer = GPT3Tokenizer.from_pretrained('gpt3')
# Define the transfer learning model architecture
transfer_model = GPT3ForSequenceClassification.from_pretrained('gpt3')
transfer_model.resize_token_embeddings(len(tokenizer))
# Define the optimizer and learning rate scheduler
optimizer = AdamW(transfer_model.parameters(), lr=5e-5)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=len(train_texts) * 3)
Step 4:
Fine-tune the model for optimal performance. This is an iterative process, and you might continuously make some tweaks depending on its performance on the task.
You should create your training loop as well. We recommend using Pytorch , but you can use any library you are comfortable with.
# Define the fine-tuning model architecture
fine_tune_model = GPT3ForSequenceClassification.from_pretrained('gpt3')
fine_tune_model.resize_token_embeddings(len(tokenizer))
fine_tune_model.classifier = torch.nn.Linear(in_features=768, out_features=2, bias=True)
# Define the optimizer and learning rate scheduler
optimizer = AdamW(fine_tune_model.parameters(), lr=2e-5)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=len(train_texts) * 3)
# Define the training loop for the transfer learning model
def train_transfer_model():
transfer_model.train()
train_loss = 0
for i in range(len(train_texts)):
input_ids = tokenizer.encode(train_texts[i], return_tensors='pt')
labels = torch.tensor([train_labels[i]], dtype=torch.long)
outputs = transfer_model(input_ids, labels=labels)
loss = outputs.loss
train_loss += loss.item()
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
return train_loss / len(train_texts)
Step 5:
At the end, you evaluate your model to see if it gives results relevant to your tasks. If it does, hurray! Well done. If it doesn’t perform well, you should iterate on previous steps and check again until satisfied with the outcome.
# Define the validation loop for the transfer learning model
def evaluate_transfer_model():
transfer_model.eval()
val_loss = 0
predictions = []
with torch.no_grad():
for i in range(len(val_texts)):
input_ids = tokenizer.encode(val_texts[i], return_tensors='pt')
labels = torch.tensor([val_labels[i]], dtype=torch.long)
outputs = transfer_model(input_ids, labels=labels)
loss = outputs.loss
val_loss += loss.item()
logits = outputs.logits
predictions.append(torch.argmax(logits, dim=1).flatten().cpu().tolist())
predictions = [item for sublist in predictions for item in sublist]
val_loss /= len(val_texts)
accuracy = accuracy_score(val_labels, predictions)
precision = precision_score(val_labels, predictions)
recall = recall_score(val_labels, predictions)
f1 = f1_score(val_labels, predictions)
return val_loss, accuracy, precision, recall
Before transfer learning and fine-tuning, ChatGPT may generate incoherent responses lacking fluency or fail to engage the user. However, fine-tuning the pre-trained model for specific tasks or domains can improve the model’s conversational performance significantly. This can result in more coherent and engaging responses for the user.
Impact of transfer learning and fine-tuning on ChatGPT’s conversational performance
This approach has led to significant improvements in natural language processing (NLP) tasks such as machine translation, sentiment analysis, and question-answering. Here are some of the impacts of transfer learning and fine-tuning on ChatGPT’s conversational performance:
- Coherence: Transfer learning helps ChatGPT to understand the context of the conversation and generate coherent responses. Fine-tuning enables the model to understand the nuances of the specific domain and provide relevant and coherent responses.
For example, a pre-trained model fine-tuned on a medical chatbot dataset can help ChatGPT understand the medical jargon, symptoms, and treatments more coherently. This can lead to more accurate responses and a better user experience.
Fluency: Transfer learning enables ChatGPT to produce fluent responses by leveraging the pre-existing knowledge of the language. Fine-tuning improves fluency by training the model with task-specific data and fine-tuning it to produce fluent responses.
Engagement: Transfer learning and fine-tuning also positively impact ChatGPT’s engagement with users. The model can understand the context of the conversation and provide personalized responses, leading to higher user engagement.
For example, a pre-trained model fine-tuned on a dataset of patient reviews and feedback can learn how to respond to patients in a more empathetic and understanding way. This can lead to increased patient satisfaction and better overall healthcare outcomes.
Importance of Transfer Learning and Fine-tuning
Transfer learning and fine-tuning approaches to model improvement have enabled significant advances in NLP, particularly in recent years with the development of large pre-trained language models like GPT-3. These models have demonstrated impressive performance on a wide range of NLP tasks, and transfer learning and fine-tuning have been critical in achieving these results.
Here are several reasons why transfer learning and fine-tuning matter in machine learning:
Efficient use of computational resources
Pre-training large language models requires significant computational resources, but transfer learning allows you to reuse pre-trained models, making it more efficient to build task-specific models.
Improved performance
Pre-trained models contain a wealth of language knowledge, making them an excellent starting point for task-specific models. Fine-tuning these models on specific datasets can improve performance on downstream tasks.
Domain-specific knowledge
Pre-trained models can be fine-tuned on domain-specific datasets, allowing them to capture the nuances of the particular domain. For example, in healthcare, you can fine-tune pre-trained models on medical text to improve their performance on tasks such as clinical decision support or medical chatbots.
However, there are also challenges associated with transfer learning and fine-tuning, including the need for large amounts of high-quality training data and the potential for overfitting. Despite these challenges, the benefits of transfer learning and fine-tuning make them indispensable machine learning techniques. They will continue to play a significant role in developing more sophisticated and powerful NLP models.
Comparison of transfer learning and fine-tuning to other techniques
We have discussed the effectiveness of transfer learning and fine-tuning in improving ChatGPT’s performance on specific tasks, but it is worth mentioning that other techniques may have their advantages and limitations, which include:
Data augmentation: Augmenting existing training data with additional synthetic examples.
Curriculum learning: Gradually increasing the complexity of the training data to improve the model’s learning ability.
Multi-task learning: Training the model to perform multiple related tasks simultaneously to improve overall performance.
| Technique | Advantages | Disadvantages |
|---|---|---|
| Transfer Learning and Fine-Tuning | - Able to leverage pre-existing knowledge. - Adaptable to new tasks and domains | - Requires pre-trained model. - May not be suitable for all applications. |
| Data Augmentation | - Increases training data volume. - Can improve model robustness. | - Requires additional data generation. - May not improve performance for all tasks. |
| Curriculum Learning | - Improves model’s ability to learn complex patterns. - Can speed up training. | - Requires careful selection of curriculum. - May not work for all models or tasks. |
| Multi-Task Learning | - Improves the model’s ability to perform multiple related tasks. - Can improve performance on individual tasks. | - Requires careful selection and design of related tasks. - May not improve performance for all tasks. |
Despite the advantages of these other techniques, transfer learning and fine-tuning can be combined to improve performance further.
Conclusion
In conclusion, transfer learning and fine-tuning are powerful techniques for enhancing ChatGPT’s conversational performance. By leveraging pre-trained models and adapting them to specific tasks and domains, these techniques allow for the creation of highly effective language models with relatively little training data.
Businesses, scientists, and engineers can create more engaging and personalized conversational experiences for their users. ChatGPT’s ability to understand and respond to natural language queries is valuable for improving customer service, healthcare, education, and entertainment.
While the technique has limitations and challenges, the potential benefits for specific use cases are substantial. As conversational AI continues to grow and evolve, these techniques will likely remain crucial for improving the performance and adaptability of pre-trained models like ChatGPT.


