
This article was published when data science tooling like Dask and R was a primary focus for Saturn Cloud. Today, Saturn Cloud is the enterprise AI platform for any GPU infrastructure.
Python is a versatile language that’s widely used in the field of data science. One of its many strengths is the ability to read and manipulate text files, which is a common requirement for data scientists. In this blog post, we’ll guide you through the process of loading a text file into Python using Jupyter Anaconda, a popular Python distribution for data science.
Table of Contents
- Introduction
- Prerequisites
- Step 1: Launch Jupyter Notebook
- Step 2: Create a New Python Notebook
- Step 3: Import Necessary Libraries
- Step 4: Define the File Path
- Step 5: Load the Text File
- Step 6: View the Data
- Pros and Cons of Text File Manipulation in Python
- Error Handling
- Conclusion
Prerequisites
Before we begin, ensure you have the following:
- Anaconda distribution installed on your system.
- A text file to work with. For this tutorial, we’ll use a simple text file named
sample.txt.
This is a sample text file for testing purposes.
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Sed vestibulum, ante a fringilla malesuada, sapien justo luctus justo, eu feugiat nulla elit in neque. Ut sit amet bibendum felis. Nullam euismod tortor eu massa vehicula, in interdum lectus auctor. Integer vel malesuada justo. Fusce sit amet felis eget velit cursus commodo. Nunc nec sapien vitae lacus facilisis pharetra vel a massa. Sed eleifend orci vel laoreet interdum. Curabitur volutpat, nisi eu vulputate efficitur, augue justo congue elit, ac pellentesque velit metus ac odio.
Phasellus ac suscipit ligula, in feugiat velit. Aenean consequat, nunc vel posuere fermentum, justo odio hendrerit sem, ut rhoncus libero ex vitae turpis. Sed euismod auctor nisl, id venenatis mauris tincidunt nec. Vivamus varius urna ut dolor imperdiet, et venenatis neque malesuada. Proin congue diam id dolor aliquet, a dictum velit aliquam. Fusce ut semper metus. Nulla facilisi. Vestibulum ac turpis vel purus auctor tincidunt. Integer auctor euismod lorem, vel luctus nisl tempus nec.
Donec eget justo vel odio fermentum tincidunt non eget felis. Quisque tristique semper metus, nec tincidunt lacus aliquet eu. Nunc feugiat, ipsum et auctor volutpat, justo lectus facilisis nulla, id malesuada sapien risus ac nunc. Praesent at ligula augue. Nam consectetur urna sit amet urna feugiat, eu hendrerit metus interdum. Sed at arcu vel urna varius feugiat id vel libero. In hac habitasse platea dictumst. Mauris rhoncus eu nisl in gravida.
Step 1: Launch Jupyter Notebook
First, launch Jupyter Notebook from the Anaconda Navigator. You can do this by clicking on the ‘Jupyter Notebook’ icon in the Anaconda Navigator interface.

Step 2: Create a New Python Notebook
Once Jupyter Notebook is running, create a new Python notebook by clicking on ‘New’ and selecting ‘Python 3’ from the dropdown menu.
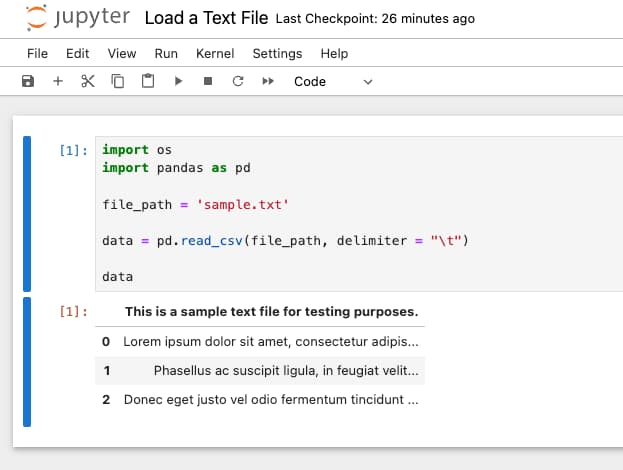
Step 3: Import Necessary Libraries
In your new Python notebook, you’ll need to import the necessary libraries. For this tutorial, we’ll be using the built-in os library to handle file paths and the pandas library to load the text file. If you don’t have pandas installed, you can do so by running !pip install pandas in a new cell.
import os
import pandas as pd
Step 4: Define the File Path
Next, define the path to your text file. Make sure the file is in the same directory as your Jupyter notebook, or provide the full path to the file.
file_path = 'sample.txt'
Step 5: Load the Text File
Now, we’re ready to load the text file. We’ll use the read_csv function from the pandas library. Although it’s primarily used for reading CSV files, it can also read text files by specifying the delimiter.
data = pd.read_csv(file_path, delimiter = "\t")
Here, we’re using \t as the delimiter, which is the symbol for tab. If your text file uses a different delimiter, such as a comma or a space, replace \t with , or respectively.
Step 6: View the Data
Finally, you can view the loaded data by simply typing the variable name and running the cell.
data
This will display the data in a tabular format, with each column representing a different field in your text file.
Pros and Cons of Text File Manipulation in Python
Pros
Ease of Use: Python’s syntax is clean and intuitive, making it accessible for beginners in data science. Its simplicity allows for quick reading and manipulation of text files.
Versatile Libraries: Python boasts powerful libraries like Pandas, which simplifies data analysis tasks. Pandas'
read_csvfunction can handle various formats of text files, making it a versatile choice.Community Support: Python has a large and active community, offering extensive resources, tutorials, and forums. This support is invaluable for troubleshooting and learning new techniques in data science.
Cons
Memory Consumption: Python can be memory-intensive, which might be a limitation when working with exceptionally large text files.
Performance Issues: For certain data-intensive operations, Python might not be as fast as compiled languages like C++ or Java, especially when dealing with very large datasets.
Complexity in Advanced Tasks: While Python is excellent for basic text file manipulation, some advanced operations might require a steep learning curve or reliance on multiple libraries.
Error Handling
- File Not Found: Handle errors related to file paths. Use a try-except block to catch
FileNotFoundErrorand provide a user-friendly message or solution.
try:
data = pd.read_csv(file_path, delimiter="\t")
except FileNotFoundError:
print("File not found. Please check the file path.")
Incorrect Delimiters: When the wrong delimiter is used, the data might not load correctly. Detecting and warning about potential incorrect delimiters can be helpful.
Encoding Issues: Text files with different encodings (like UTF-8, ASCII) can cause errors. Implement error handling to manage different encoding standards or malformed files.
Large File Handling: For large files, reading the entire file at once might not be feasible. Implement solutions like reading in chunks to handle large files efficiently.
Dataframe Issues: Errors can occur if the data doesn’t fit into a tabular format as expected. Handling exceptions related to Pandas dataframes is crucial.
Conclusion
Loading a text file into Python using Jupyter Anaconda is a straightforward process. With just a few lines of code, you can read and manipulate text data, making Python an invaluable tool for data scientists.
Remember, the key to mastering Python and data science is practice. So, keep experimenting with different text files and delimiters, and explore the various functions that the pandas library offers for manipulating data.

