
Saturn Cloud is an MLOps platform that works on any cloud and for teams of all sizes. Now, users can supercharge AI inference on Saturn Cloud with NVIDIA NIM inference microservices, making it easier for developers to build and deploy generative AI apps and helping enterprises maximize infrastructure efficiency.
What is NVIDIA NIM?
NVIDIA NIM is a set of inference microservices that help enable the deployment of generative AI models, including large language models (LLMs), in any environment, whether in the cloud, on-premises data centers, or GPU-accelerated workstations. NIM packages optimized inference engines with industry-standard APIs and support for all major foundation models into easily deployable containers.
NIM offers several key advantages over building your own Docker containers.
- Optimized Inference Engines: NIM leverages NVIDIA’s optimized inference engines to provide low latency and high throughput, helping ensure efficient use of GPU resources. This setup reduces the cost of running inference workloads and improves end-user experiences by scaling to meet demand seamlessly.
- Scalable Deployment: NIM supports deployment across various infrastructures, including Kubernetes clusters, cloud environments, and on-premises servers. This flexibility allows enterprises to scale their AI applications as needed.
- Secure and Flexible Integration: NIM helps ensure data privacy and security during inference processing. Its design allows for easy integration into existing workflows and applications through multiple API endpoints.
- Support for Enterprise-Grade AI: As part of the NVIDIA AI Enterprise software platform, NIM includes features like enterprise-grade support, regular security updates, and rigorous validation, making it suitable for production environments.
Deploying NVIDIA NIM on Saturn Cloud
Saturn Cloud offers resource templates to help you get started with NIM as quickly as possible. NIM microservices are currently available with a 90-day NVIDIA AI Enterprise evaluation license. An NVIDIA AI Enterprise license is required to use NIM in production.
Prerequisites
- Importing NIM images into your private container registry. If you are a Saturn Cloud Enterprise customer, please contact support@saturncloud.io, and our support team can set this up for you.
- Obtaining your NVIDIA NGC API key. This key authenticates you with the NVIDIA GPU Cloud. A valid NGC API key is required to run NIM.
Adding your NVIDIA NGC API key to Saturn Cloud
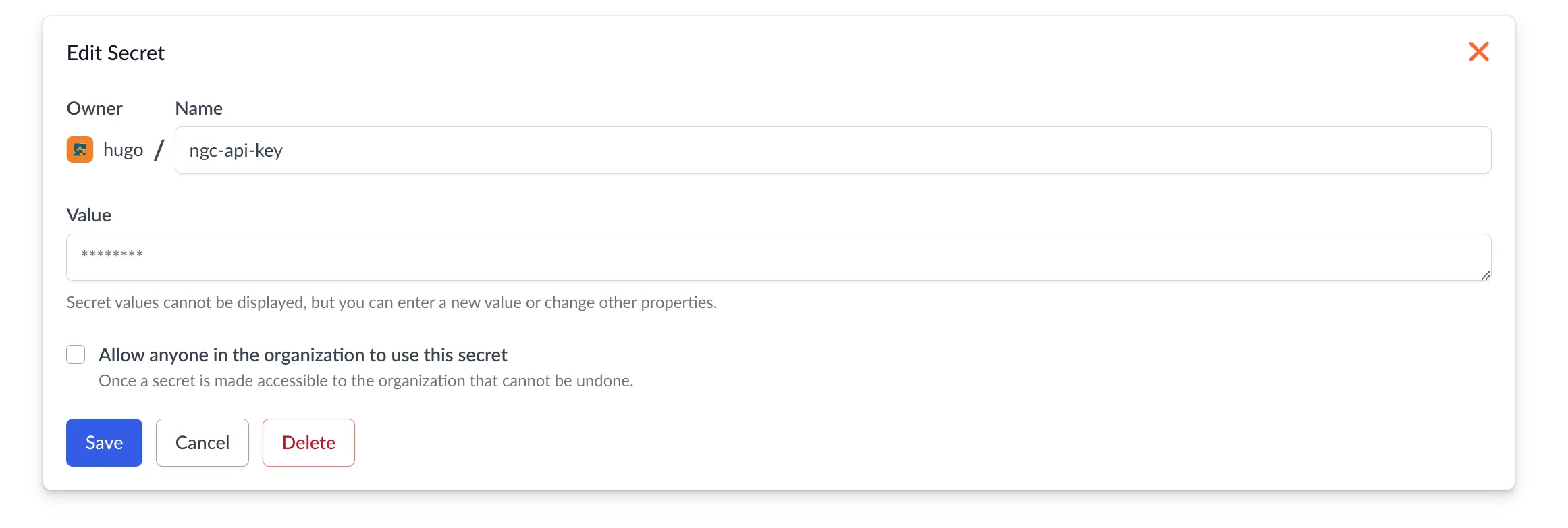
Saturn Cloud has a built-in secrets manager for storing sensitive information encrypted in our database, which can then be exposed to resources you deploy in Saturn Cloud. These are typically passwords or API keys for other services. To add your NGC API Key, the first step is to click on “Secrets” in the sidebar and paste your NGC API Key into your Saturn Cloud account as shown below.
We have created a resource template (see below image) which can seamlessly deploy NIM for the Llama 3 8b model.
Once you click on the template, choose a name for your new microservice deployment.
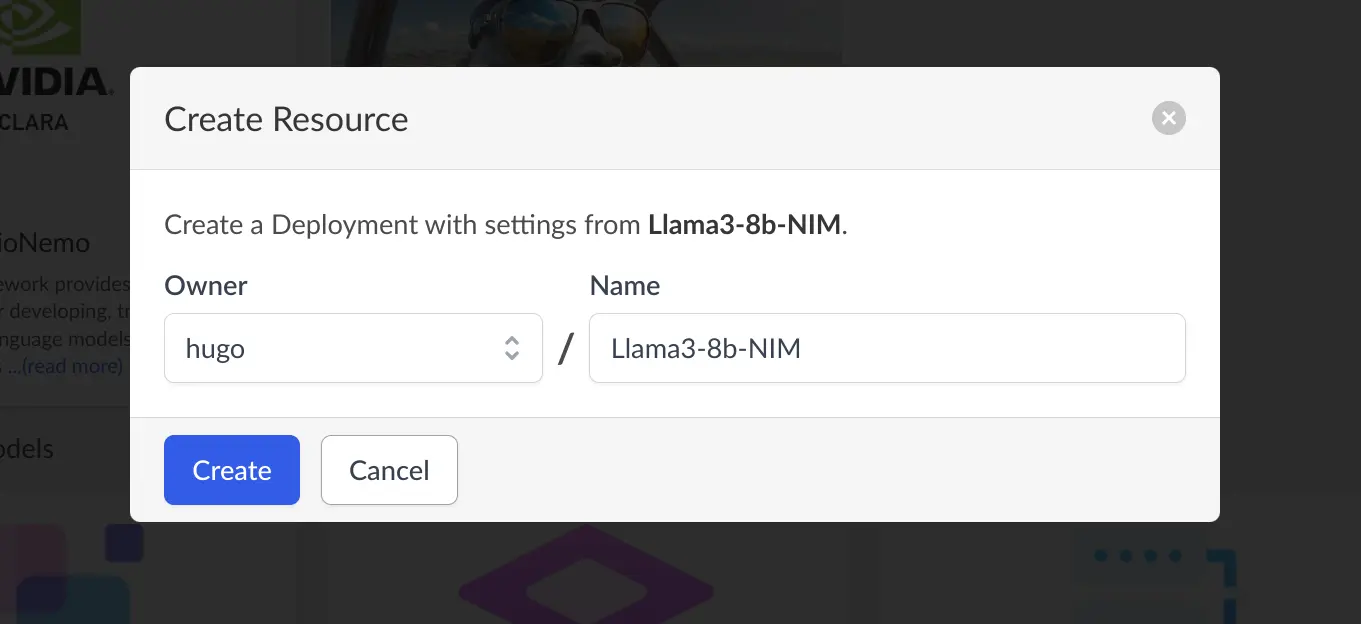
After it is created, click the start button to deploy it. Once the microservice is started, the URL of the microservice will be shown on the screen, which shows where the NIM is deployed. For example, this NIM is deployed to the following URL. https://pd-hugo-llama3-8b-n-8d1ba34fc39f4e70a2eea96256d7e467.internal.saturnenterprise.io.
NIM exposes a route at v1/models that list all models available in the NIM. The endpoint can be reached by accessing this url: https://pd-hugo-llama3-8b-n-8d1ba34fc39f4e70a2eea96256d7e467.internal.saturnenterprise.io/v1/models
which returns:
{"object":"list","data":[{"id":"meta-llama3-8b-instruct","object":"model","created":1717205802,"owned_by":"system","root":"meta-llama3-8b-instruct","parent":null,"permission":[{"id":"modelperm-3414fb42b6d8486da9fd34f3713b9442","object":"model_permission","created":1717205802,"allow_create_engine":false,"allow_sampling":true,"allow_logprobs":true,"allow_search_indices":false,"allow_view":true,"allow_fine_tuning":false,"organization":"*","group":null,"is_blocking":false}]}]}
The above URL is running on our own deployment instance of Saturn Cloud enterprise. When you deploy a NIM on your Saturn Cloud enterprise instance, you will receive your own distinct URL.
Run inference using NIM APIs
Once NIM is deployed, it can start serving the model behind an API endpoint. NIM uses OpenAI APIs to execute completion inference requests. The OpenAI Python API client or curl can be used to run the inference as below.
>>> import requests
>>> from openai import OpenAI
>>> headers = {'Authorization': f'token {os.getenv("SATURN_TOKEN")}'}
>>> base_url = "https://pd-hugo-llama3-8b-n-8d1ba34fc39f4e70a2eea96256d7e467.internal.saturnenterprise.io/v1"
>>> client = OpenAI(
... base_url=base_url,
... default_headers=headers,
... api_key="not-used")
>>> requests.get(base_url + "/models", headers=headers).json()
{'object': 'list', 'data': [{'id': 'meta-llama3-8b-instruct', 'object': 'model', 'created': 1717115247, 'owned_by': 'system', 'root': 'meta-llama3-8b-instruct', 'parent': None, 'permission': [{'id': 'modelperm-fb9f805d46de49cfb5fddae11abb31ab', 'object': 'model_permission', 'created': 1717115247, 'allow_create_engine': False, 'allow_sampling': True, 'allow_logprobs': True, 'allow_search_indices': False, 'allow_view': True, 'allow_fine_tuning': False, 'organization': '*', 'group': None, 'is_blocking': False}]}]}
In the above example, we set headers to authenticate with Saturn Cloud. Then, we initialized an OpenAI client using the base_url from our deployment URL, with default_headers referencing the Saturn Cloud API Token. Finally, we executed a request to list all models on the server (currently just meta-llam3-8b-instruct).
Next, we used the OpenAI API to create a chat completion, asking Llama 3 for a chocolate cake recipe:
>>> prompt = "please write me a recipe for a chocolate cake"
>>> response = client.completions.create(model="meta-llama3-8b-instruct", prompt=prompt, stream=False, max_tokens=250)
>>> print(response.choices[0].text)
!
Recipe: Rich, Fudgy, and Moist Chocolate Cake
**Makes:** 2 (9-inch) round cakes
**Ingredients:**
For the cake:
* 1 1/2 cups (190g) all-purpose flour
* 1 cup (200g) granulated sugar
* 2 teaspoons baking powder
* 1 teaspoon baking soda
* 1 cup (240ml) whole milk, at room temperature
* 2 large eggs, at room temperature
* 1/2 cup (120ml) unsweetened cocoa powder, at a glance
* 1 teaspoon vanilla extract
* 1/4 teaspoon salt
For the chocolate ganache:
* 1 cup (200g) unsalted butter, at room temperature
* 2 cups (250g) dark chocolate chips (at least 60% cocoa; more preferred)
**Instructions:**
1. Preheat your oven to 350°F (180°C) and prepare 2 (9-inch) round cake pans. Grease the pans with butter and line the bottoms with parchment paper.
2. In a medium bowl, whisk together flour, sugar, baking powder, and salt.
3. In a large mixing bowl
>>> print(response.choices[1].text)
How does this work?
Saturn Cloud resources execute docker containers, along with:
- code from your Git repositories
- NFS mounts
- attached IAM roles
- attached secrets
- any custom init scripts or package installations
Some resources (workspaces) are focused on research and development, for example, Jupyter Lab servers and R Studio servers. Other resources (jobs) are focused on executing ETL jobs or retraining jobs. Finally, deployments are used to deploy APIs, ML models, and dashboards. In this blog post, we are creating a deployment with the Llama 3 NIM.
The following YAML is the recipe for the deployment of NIM microservice.
type: deployment
spec:
name: Llama3-8b-NIM
description: NIM for llama3
command: /opt/nvidia/nvidia_entrypoint.sh /opt/nim/start-server.sh
image: saturncloud/meta-llama3-8b-instruct:24.05.rc9
instance_type: g5xlarge
environment_variables: {}
secrets:
- location: NGC_API_KEY
type: environment_variable
description: ""
name: ngc-api-key
A few key parts of the recipe:
- command: This is the command line that will be executed for the docker container. In this case, we have selected the NVIDIA entrypoint for starting up the NIM microservice.
- image: This is the image from NGC that has been imported into your private registry.
- instance_type: This is the instance that will be used. For the example, we’ve selected a g5.xlarge instance on AWS, which has an NVIDIA A10G GPU.
- secrets: This maps a secret from your account (named ngc-api-key) to the NGC_API_KEY environment variable. NIM containers require this API key in order to run.
Saturn Cloud resources are general data science resources. In this case, we are configuring it to deploy the NIM microservice. But you can see how this approach can be used to deploy arbitrary workflows.
Networking and access control for NVIDIA NIM
Once your NIM is deployed, there are a few settings you may want to adjust.
Subdomain
If you click on the “edit” button for the deployment, you can choose an explicit subdomain. This NIM had an auto-generated subdomain of pd-hugo-llama3-8b-n-8d1ba34fc39f4e70a2eea96256d7e467. You may want to choose a much more human-readable subdomain, such as llama3. The domain itself .internal.saturnenterprise.io is the domain of the Saturn Cloud installation. This cannot be changed.
Network Access
Saturn Cloud deployments default to granting access to everyone in the organization.
The networking tab can be used to control access to your NIM. For example, if you wanted the NIM to specific users at your company, you would click on the edit button, and change the visibility from “Anyone in the organization” to “only the owner.” After that, you can use the Viewers section to explicitly grant access to specific users or groups. Accessing deployed APIs is simply a matter of accessing the http endpoint with the necessary API token passed through via http headers.
Conclusion
Deploying generative AI on Saturn Cloud using NVIDIA NIM provides a practical and efficient solution for scaling AI models. By integrating NIM on Saturn Cloud, developers can achieve greater performance and reliability in their AI applications.
Saturn Cloud’s infrastructure combined with NVIDIA NIM simplifies the deployment process and improves model efficiency. This approach addresses common challenges in AI deployment, offering a seamless and scalable solution.
Saturn Cloud with NVIDIA NIM offers a robust framework for deploying generative AI. It delivers the necessary performance, scalability, and ease of use to support AI-driven projects, helping ensure the successful and effective deployment of AI models.

