
In this blog post, we will walk you through the process of building a Question and Answering chatbot using Llama, Vicuna and Bert. This is similar to our previous blog post that was building a pure chatbot, however this application will search through a corpus of documents, which the language model will use as context for answers. We have a number of enterprise customers that are looking for easy ways to search and chat with proprietary research documents in their organization. This example serves as a good starting point for building projects like that.
The code for this chatbot is hosted on GitHub. You can also run it directly in Saturn Cloud:

Motivations and Background
Language models are not knowledge models. They are really good at predicting the upcoming text given a passage, but they don’t know anything about the text they’re generating. Many companies have large collections of proprietary documents that they would like to be able to query efficiently. You can definitely throw those documents into a search engine, however users still have to read the individual documents in order to gain insight. The goal of this work is to provide a chat interface to querying proprietary documents that is safe and secure. Since many companies are concerned about leaking proprietary information to ChatGPT, we are using the Vicuna model here. You can generally replace Vicuna with other well performing language models, such as Llama 2, or Chat GPT if you are ok sending proprietary data to Open AI.
We have designed this project to be generalizable to all domains. However our specific dataset for the example are papers related to cardiology from PubMed. If you run our code out of the box, it will be configured to do QA chat on PubMed cardiology papers, however this respository also serves as a starting point for building your own QA chatbot.
Flow of the QA bot
In our design, the user submits a question. We use semantic search to query relevant documents. Those documents are provided as context to the language model, which attempts to answer the users question given that context. Subsequent questions are rephrased to form good search queries, and the cycle repeats until the user is done interacting with the model.
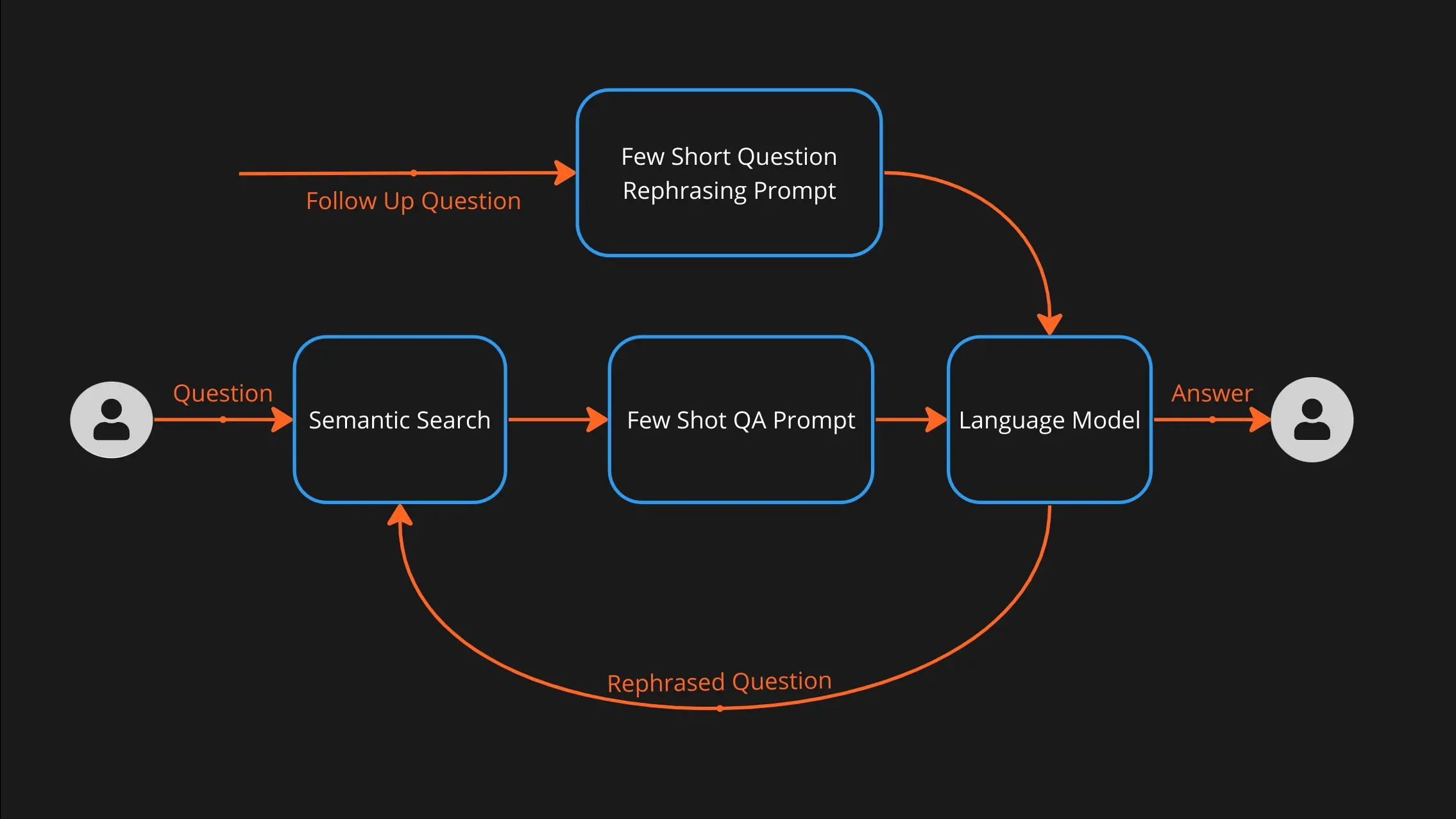
Semantic Search
The goal of semantic search is to match a phrase (the question) with another phrase (the answer) from a corpus of documents. We use Bert to compute vectors (embeddings) from the question, as well as documents, and we find the top 3 documents that match the users question. For the PubMed use case, we use a sentence transformers model (pritamdeka/S-PubMedBert-MS-MARCO) which is based on microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext but fine tuned on the MS Marco dataset. IF you are building your own QA bot on your proprietary documents, we recommend sentence-transformers/multi-qa-mpnet-base-dot-v1.
What is Bert?
BERT (Bidirectional Encoder Representations from Transformers) is a natural language processing (NLP) model developed by Google in 2018. The embeddings produced by BERT were optimized for 2 tasks:
- Masked Language Modeling (MLM): During pre-training, random words in the input text are masked. The model’s objective is to predict these masked words based on the surrounding context. This process forces the model to understand the bidirectional context and learn word representations in context.
- Next Sentence Prediction (NSP): In addition to MLM, BERT is trained to predict if one sentence follows another in the original text. This helps the model capture relationships between sentences and is especially useful for tasks like question answering and natural language inference.
What is Sentence Bert?
The models we use for semantic search are based on Sentence-BERT. Sentence-BERT, does not use masked language modeling or next sentence prediction during pre-training. Instead, it uses a siamese or triplet network architecture to learn similarity-based representations for sentences. It leverages contrastive learning to bring similar sentences closer in the embedding space and push dissimilar sentences apart. Sentence Bert is trained on sentence pairs to obtain embeddings such that similar sentences have smaller distances from dissimilar sentences.
MS MARCO Dataset
MS MARCO (Microsoft MAchine Reading COmprehension) is a large-scale dataset and a set of benchmarks for machine reading comprehension and question answering tasks. It was created by Microsoft Research to advance the research and development of question-answering systems. The dataset is designed to test the ability of natural language understanding models to comprehend and answer questions posed by humans. The models we use were trained on MS MARCO, specifically on tasks focused on tying questions to passages that contain the answer. MS MARCO helps obtain good distance vectors for questions and answers, which is useful because in many situations questions, which are short, would naturally have large distances from the relevant answers, which can be quite lengthy.
Using Sentence Bert trained with MS MARCO helps us obtain embeddings that are good to help us find documents in the corpus which are a good fit for the users question.
In Context Learning vs Fine Tuning
It’s worth pointing out that a reasonable alternative to semantic search is to simply fine-tune your model on your proprietarydocuments. Fine-tuning involves updating the weights of the LLM using a small dataset of labeled examples for the new task. This can be a time-consuming and computationally expensive process, especially for large LLMs.
In-context learning does not involve updating the weights of the LLM. Instead, the LLM is given a few examples of the new task, along with a prompt that tells the LLM how to interpret the examples. The LLM then learns to perform the new task by simply reading the examples and the prompt.
Here is a table that summarizes the key differences between in-context learning and fine-tuning:
| Feature | In-context learning | Fine-tuning |
|---|---|---|
| Updates weights | No | Yes |
| Requires labeled data | No (except a few examples) | Yes (a large dataset) |
| Computational complexity | Low | High |
| Out-of-domain generalization | Good | Good, but can overfit |
| Spurious correlations | Less likely | More likely |
Note: this is an open area of research. New papers are being produced about the advantages and disadvantages of both approaches.
Advantages of in-context learning
- Simple and efficient
- Good out-of-domain generalization
- Less likely to pick up on spurious correlations
Advantages of fine-tuning
- Can achieve higher accuracy on in-domain tasks
- More flexible (can be used with a wider variety of tasks)
- Fine-tuning can save valuable context space because you don’t have to encode examples in the prompt
Why we use in-context learning
For this use case specifically, there are 3 main reasons we have elected to incorporate documents into the context
Fine grained document permissions. In an enterprise use case, different users have access to different sets of documents. Our example does not handle this use case out of the box, but we expect users to extend it to handle this use case. In order to present different knowledge bases to different users, the knowledge base must be managed in context, rather than in the model weights. Otherwise you would have to train a different model per user.
Model size limitations. When you fine tune a language model, that new information is incorporated into the model weights. There must be some relationship between the size of the dataset and the size of the language model. Since working with large models is difficult (GPUs are expensive, and this would also require sharding larger models) ther are big advantages to keeping knowledge out of the model.
Knowledge cut-offs. Adding new documents to semantic search is just an issue of computing embeddings for the new documents and adding them to your vector store. Adding new data to the model requires fine-tuning it again.
Answer a question with context
When a new question comes in, the first step is to use semantic search to find sentences in your corpus of documents that can answer the question. The second step is to have the language model answer the question using the search results.
We use the following prompt:
Given the following contexts and a question, create a final answer. Only use the given context to arrive at your answer. If you don't know the answer, just say that you don't know. Don't try to make up an answer.
Context: No Waiver. Failure or delay in exercising any right or remedy under this Agreement shall not constitute a waiver of such (or any other) right or remedy.11.7 Severability. The invalidity, illegality or unenforceability of any term (or part of a term) of this Agreement shall not affect the continuation in force of the remainder of the term (if any) and this Agreement.11.8 No Agency. Except as expressly stated otherwise, nothing in this Agreement shall create an agency, partnership or joint venture of any kind between the parties.11.9 No Third-Party Beneficiaries.
Context: This Agreement is governed by English law and the parties submit to the exclusive jurisdiction of the English courts in relation to any dispute (contractual or non-contractual) concerning this Agreement save that either party may apply to any court for an injunction or other relief to protect its Intellectual Property Rights.
Context: (b) if Google believes, in good faith, that the Distributor has violated or caused Google to violate any Anti-Bribery Laws (as defined in Clause 8.5) or that such a violation is reasonably likely to occur,
Question: Which state/country's law governs the interpretation of the contract?
Answer: This Agreement is governed by English law.
Question:
Context: Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet.
Context: More support for patients and families. To get there, I call on Congress to fund ARPA-H, the Advanced Research Projects Agency for Health. It's based on DARPA—the Defense Department project that led to the Internet, GPS, and so much more. ARPA-H will have a singular purpose—to drive breakthroughs in cancer, Alzheimer's, diabetes, and more.
Question: What did the president say about Michael Jackson?
Answer: I don't know.
Question: What is the purpose of ARPA-H?
Answer: The Advanced Research Projects Agency for Health will drive breakthroughs in cancer, Alzheimer's, diabetes, and more.
Question:
This prompt provides examples of what we want the language model to do. We provide the language model with multiple contexts, and then have it answer the question. This includes a question/answer pair that teaches the model to say “I don’t know” if the answer doesn’t existing in the context. Single shot prompts provide the language model with one example, and few shot prompts provide the language model with multiple examples. There is a natural tradeoff here because language models are constrained to the maximum number of tokens they can process. The longer the prompt, the less space there is for other information (in this case, that would be search results)
If I ask the question “What is Losartan”, Combining the above prompt with real search results, we send the following to the language model:
Given the following contexts and a question, create a final answer. Only use the given context to arrive at your answer. If you don't know the answer, just say that you don't know. Don't try to make up an answer.
Context: No Waiver. Failure or delay in exercising any right or remedy under this Agreement shall not constitute a waiver of such (or any other) right or remedy.11.7 Severability. The invalidity, illegality or unenforceability of any term (or part of a term) of this Agreement shall not affect the continuation in force of the remainder of the term (if any) and this Agreement.11.8 No Agency. Except as expressly stated otherwise, nothing in this Agreement shall create an agency, partnership or joint venture of any kind between the parties.11.9 No Third-Party Beneficiaries.
Context: This Agreement is governed by English law and the parties submit to the exclusive jurisdiction of the English courts in relation to any dispute (contractual or non-contractual) concerning this Agreement save that either party may apply to any court for an injunction or other relief to protect its Intellectual Property Rights.
Context: (b) if Google believes, in good faith, that the Distributor has violated or caused Google to violate any Anti-Bribery Laws (as defined in Clause 8.5) or that such a violation is reasonably likely to occur,
Question: Which state/country's law governs the interpretation of the contract?
Answer: This Agreement is governed by English law.
Question:
Context: Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet.
Context: More support for patients and families. To get there, I call on Congress to fund ARPA-H, the Advanced Research Projects Agency for Health. It's based on DARPA—the Defense Department project that led to the Internet, GPS, and so much more. ARPA-H will have a singular purpose—to drive breakthroughs in cancer, Alzheimer's, diabetes, and more.
Question: What did the president say about Michael Jackson?
Answer: I don't know.
Question: What is the purpose of ARPA-H?
Answer: The Advanced Research Projects Agency for Health will drive breakthroughs in cancer, Alzheimer's, diabetes, and more.
Question:
Context: Losartan is the first of a new class of antihypertensive agents called 'angiotensin II antagonists'. ...
Context: ...
Context: ...
Context: ...
Context: ...
Question: What is Losartan
Answer:
This results in an answer like
Losartan is an angiotensin II receptor antagonist (AT1 selective) which has undergone extensive clinical trials for the treatment of hypertension. It is an orally-active, selective, nonpeptide, angiotensin II type 1-receptor antagonist (ARB). It was the first in this class to be marketed. Several large-scale clinical trials have demonstrated that losartan and other ARBs have benefits in preventing cardiovascular disease. The Losartan Intervention For End point reduction in hypertension (LIFE) study demonstrated improved outcomes with losartan as compared with atenolol-based therapies in hypertensive patients with left ventricular hypertrophy, mainly because of stroke prevention. The Reduction of End points in Non-insulin-dependent diabetes mellitus with the Angiotensin II Antagonist Losartan (RENAAL) study demonstrated that losartan prevented the progression of diabetic nephropathy. In this review, evidence from these and other clinical trials with losartan shall be discussed. The pharmacodynamic and pharmacokinetic properties of losartan are described to explain its mechanisms of action.
Question Rephrasing
If the user asks a follow up question
What are other similar drugs?
We cannot pass that straight into semantic search because we have lost all context for which drug we are referring to. In order to use semantic search on follow up questions, we first ask the language model to rephrase the question as a standalone question. This results in a question like
What are some similar drugs to Losartan?
We again accomplish this using a few shot prompt as follows:
Given the following conversation and a follow up question, rephrase the follow up question with any relevant context.
Question: What is the purpose of ARPA-H?
Answer: The Advanced Research Projects Agency for Health will drive breakthroughs in cancer, Alzheimer's, diabetes, and more.
Question: When was it created?
Standalone Question: When was the Advanced Research Projects Agency for Health created?
Question: What is the purpose of ARPA-H?
Answer: The Advanced Research Projects Agency for Health will drive breakthroughs in cancer, Alzheimer's, diabetes, and more.
Question: When was it created?
Answer: The Advanced Research Projects Agency for Health was created on March 15, 2022
Question: What are some of the other breakthroughs?
Standalone Question: In addition to cancer, Alzheimer's, and diabetes, what are some other breakthroughs driven by the Advanced Research Projects Agency for Health?
Question: Which state/country's law governs the interpretation of the contract?
Answer: This Agreement is governed by English law.
Question: Who are the primary parties bound by the contract?
Standalone Question: Who are the primary parties bound by the contract?
{conversation}
Question: {question}
Standalone Question:
The resulting question gets fed back into the language model to continue the conversation
Conclusion
To run this in Saturn Cloud, click the link below:
This article we have attempted to provide you with the intuition needed to build a QA bot powered with a corpus of your companies proprietary documents. The included Saturn Cloud template will be a fast way for you to experiment with these ideas, and possibly extend it to your own internal documents.


