
This article was published when data science tooling like Dask and R was a primary focus for Saturn Cloud. Today, Saturn Cloud is the enterprise AI platform for any GPU infrastructure.
As a data scientist or software engineer, you are always looking for ways to improve the performance and accuracy of your machine learning models. One way to do this is by utilizing GPUs (Graphics Processing Units) for faster training and inference. In this article, we will explore how to use AWS SageMaker on GPU for high-performance machine learning.

Table of Contents
- What is AWS SageMaker?
- Why use GPUs for Machine Learning?
- How to Use AWS SageMaker on GPU
- Best Practices
- Conclusion
What is AWS SageMaker?
AWS SageMaker is a cloud-based service that provides an integrated development environment (IDE) for building, training, and deploying machine learning models. It offers a range of tools and services that make it easy to build, train, and deploy machine learning models at scale.
SageMaker provides a range of built-in algorithms for common machine learning tasks such as image classification, regression, and clustering. It also allows you to bring your own custom algorithms and frameworks.
Why use GPUs for Machine Learning?
GPUs are highly parallel processors that can perform computations much faster than CPUs (Central Processing Units). This makes them ideal for machine learning tasks, which involve heavy computations such as matrix multiplication and convolution.
Using GPUs in machine learning can significantly speed up training times, allowing you to iterate on your models faster and achieve better results. GPUs also enable real-time inference, which is important for applications such as self-driving cars and real-time fraud detection.
How to Use AWS SageMaker on GPU
AWS SageMaker makes it easy to use GPUs for machine learning by providing pre-configured instances with NVIDIA GPUs. These instances are optimized for machine learning workloads and come with pre-installed frameworks such as Tensorflow and PyTorch.
To use AWS SageMaker on GPU, follow these steps:
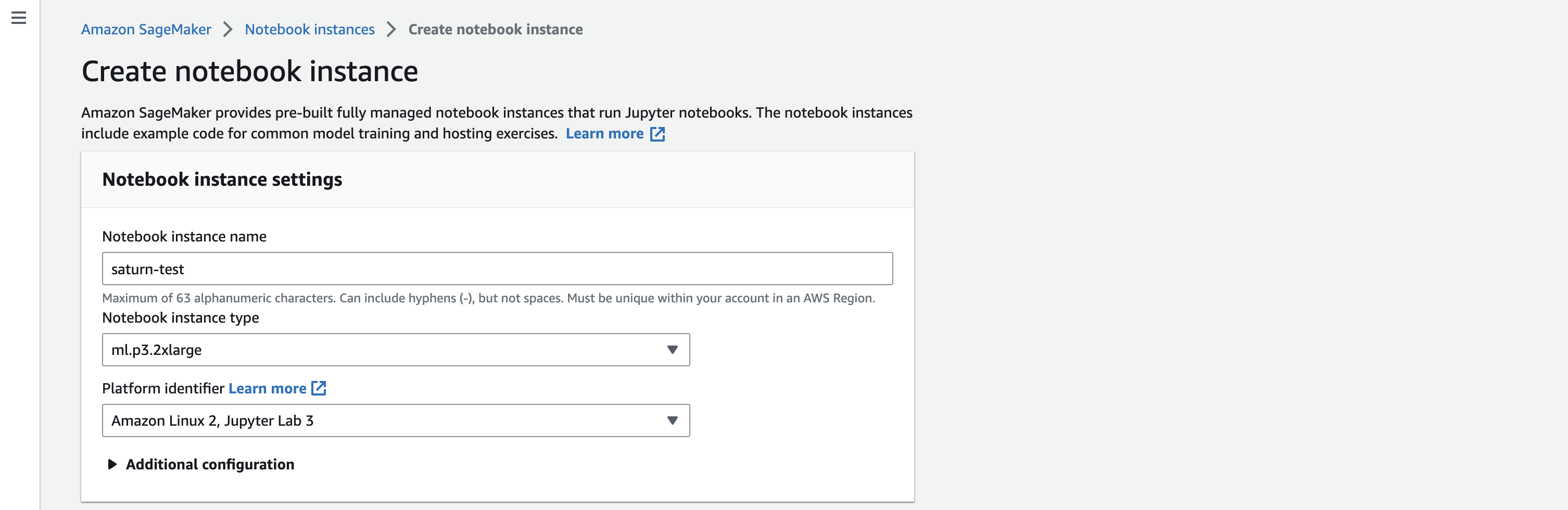
Step 1: Create a Notebook Instance
To use SageMaker, you need to create a notebook instance. A notebook instance is a fully managed Amazon EC2 instance that you can use to run Jupyter notebooks.
- Open the SageMaker console and click on “Notebook instances”.
- Click on “Create notebook instance”.
- Choose an instance type that has a GPU, such as “ml.p3.2xlarge”.
- Choose a VPC and subnet for your instance.
- Choose an IAM role that grants SageMaker permissions to access resources in your account.
- Click on “Create notebook instance”.
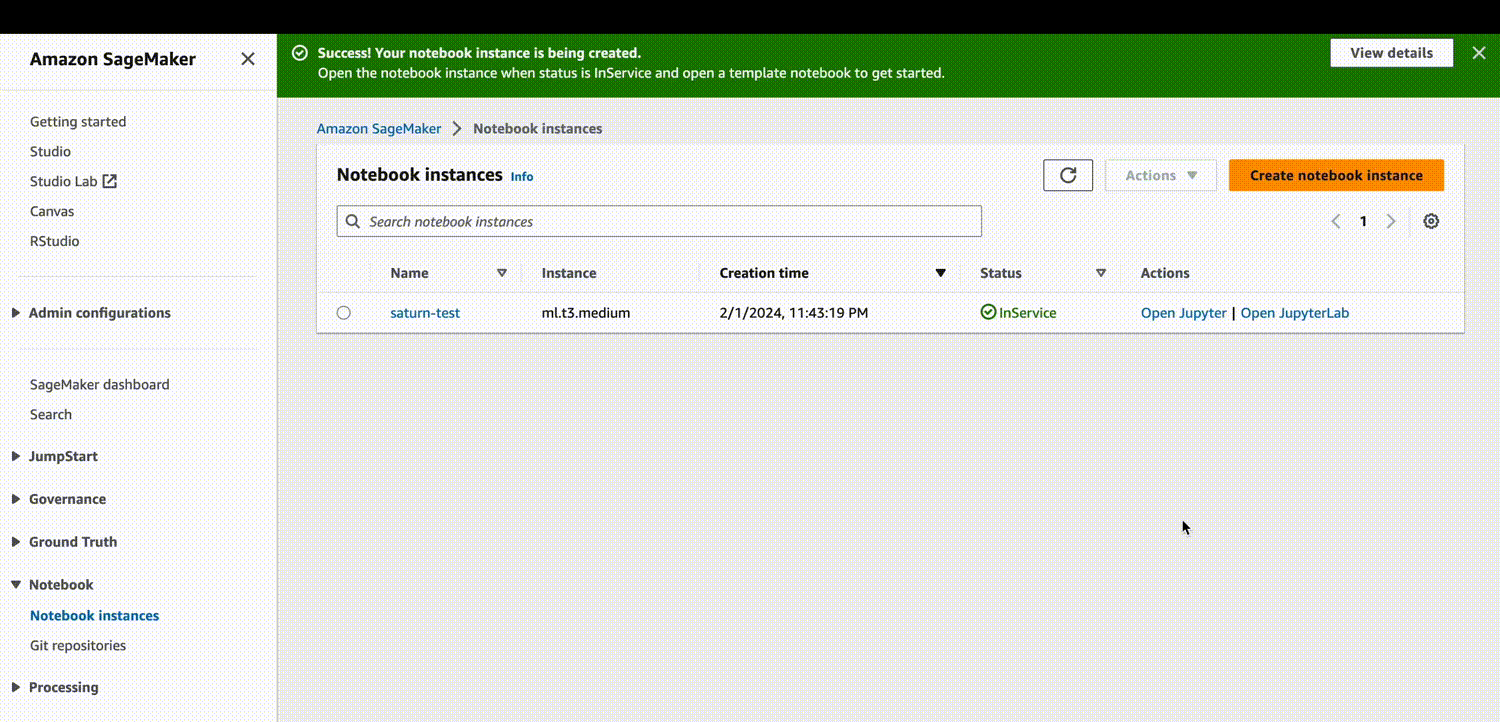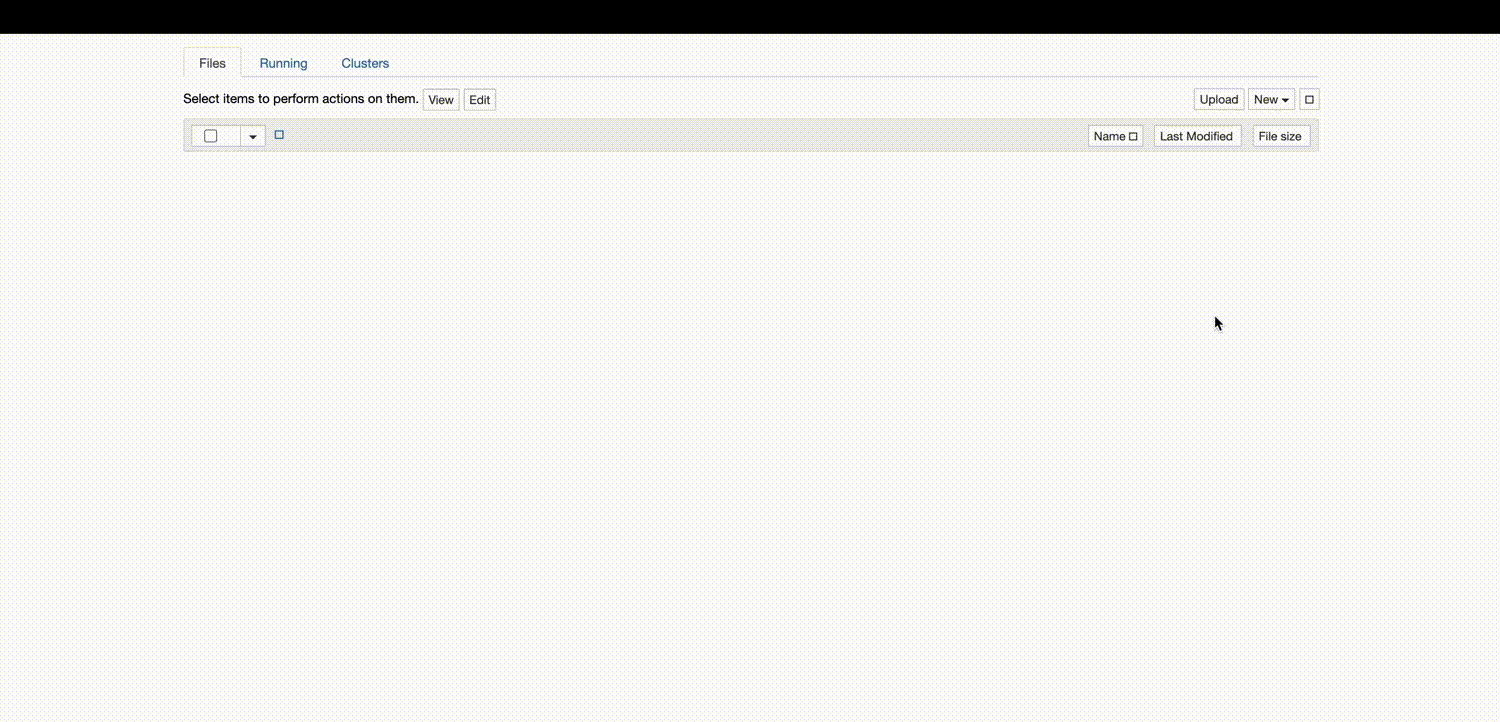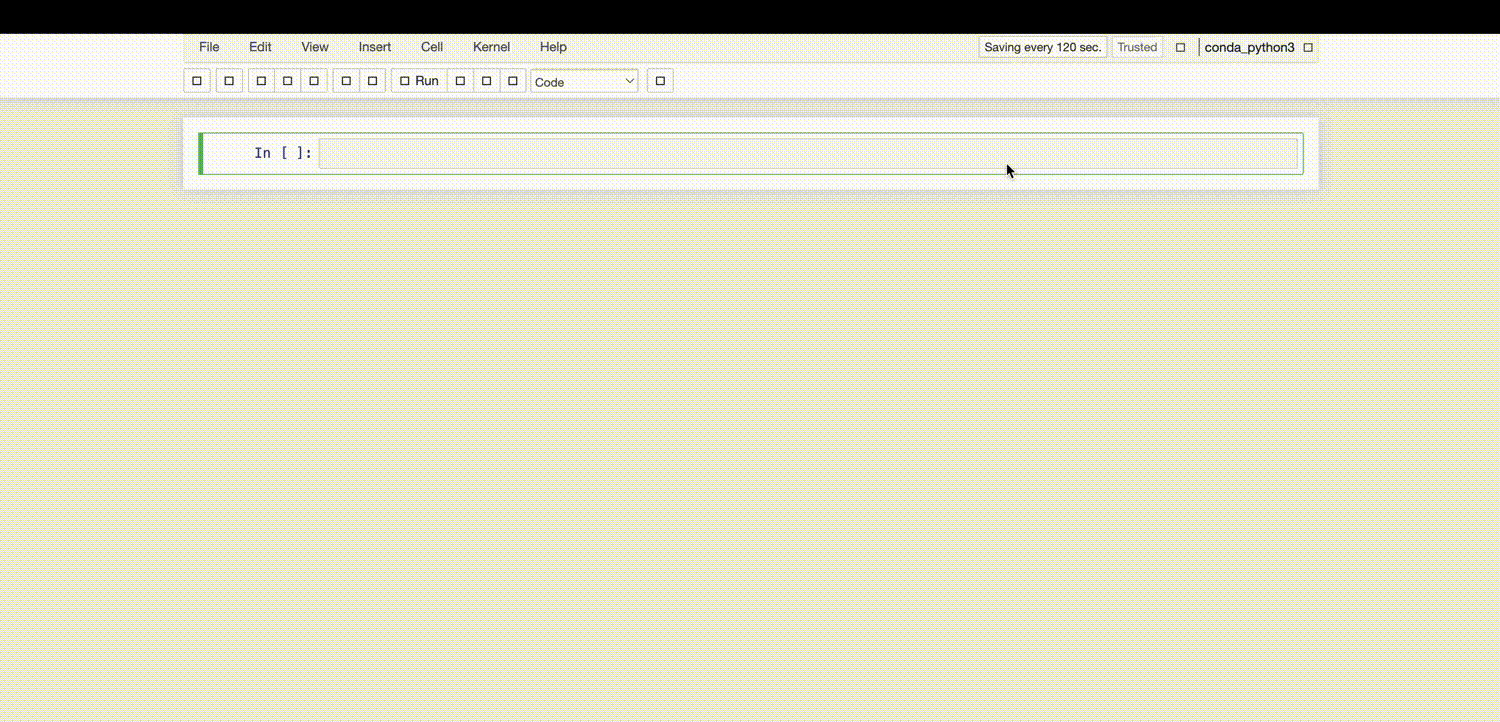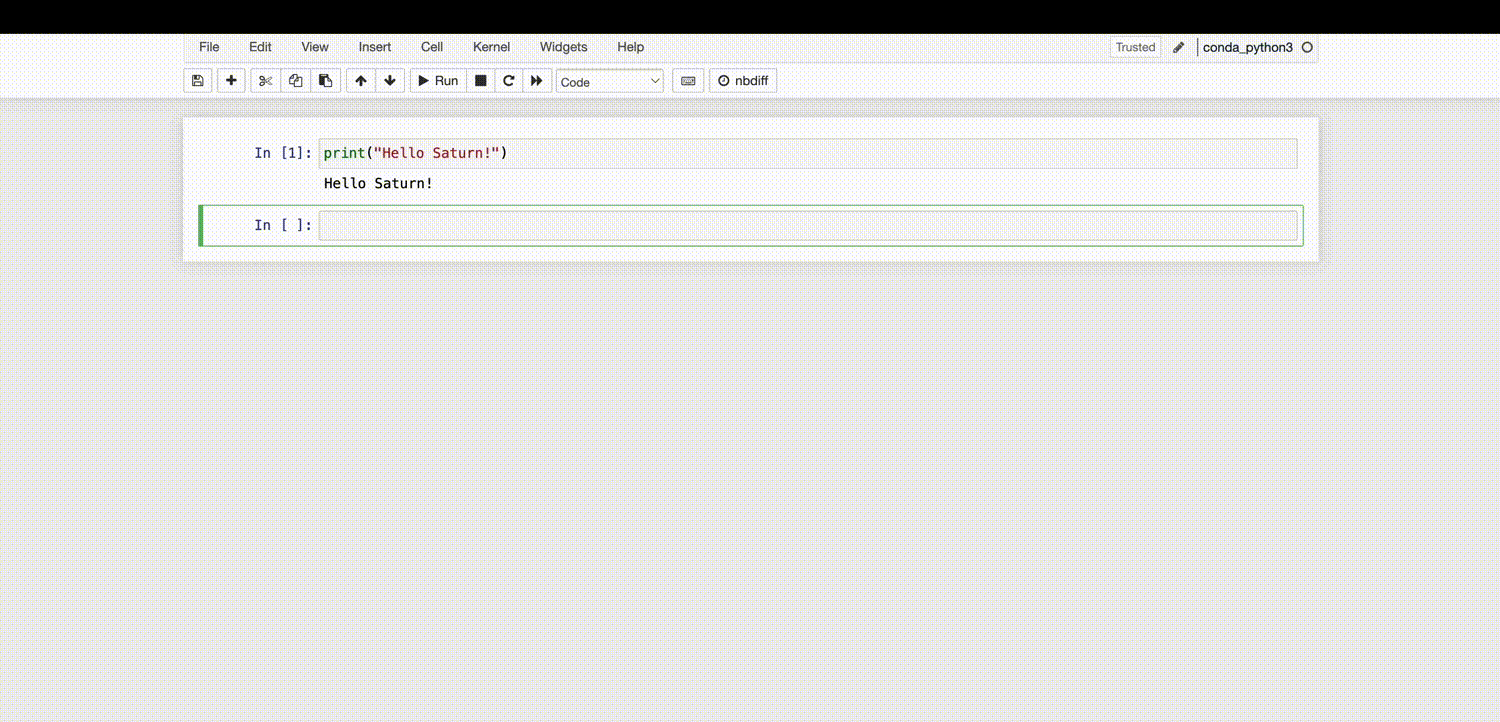
Step 2: Open Jupyter Notebook
Once your notebook instance is created, you can open Jupyter Notebook in your web browser.
- Click on “Open Jupyter” to launch Jupyter Notebook.
- Create a new notebook by clicking on “New” and selecting “Python 3”.
- In the first cell, import the necessary libraries and set up the environment for GPU training. For example:
import tensorflow as tf
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.Session(config=config)
Step 3: Train Your Model on GPU
With your notebook set up for GPU training, you can now train your machine learning model on the GPU.
- Load your data into the notebook using a library such as Pandas or NumPy.
- Preprocess your data and split it into training and validation sets.
- Define your model using a deep learning framework such as Tensorflow or PyTorch.
- Train your model on the GPU by calling the “fit” method on your model. For example:
model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=10, batch_size=32)
Step 4: Deploy Your Model with SageMaker
Once your model is trained, you can deploy it using SageMaker.
- Save your trained model to a file using a library such as Keras or PyTorch.
- Upload the model file to S3 using the SageMaker console or the AWS SDK.
- Create a SageMaker endpoint by specifying the instance type and the model file location.
- Test your endpoint by making predictions on new data.
Best Practices:
Choose the Right Instance Type: When launching an AWS SageMaker notebook instance, carefully select the instance type that aligns with your machine learning workload requirements. SageMaker offers various GPU-enabled instances like p3 and g4 instances. Consider factors such as available memory, processing power, and cost implications.
Optimize Data Loading and Preprocessing: Efficient data loading and preprocessing can have a significant impact on GPU utilization. Optimize your data pipelines to ensure that data is fed to the GPU efficiently. Utilize parallel processing capabilities to enhance data throughput and minimize idle GPU time.
Utilize GPU-Accelerated Libraries: Leverage GPU-optimized libraries and frameworks such as TensorFlow and PyTorch. These libraries are designed to take advantage of GPU capabilities and can significantly improve the performance of machine learning tasks.
Implement Batch Processing: Batch processing allows you to make the most out of GPU parallelism. Instead of processing data point by point, consider batching multiple data points together. This can enhance the efficiency of GPU utilization and speed up model training.
Monitor and Optimize GPU Utilization: Regularly monitor GPU utilization during model training. Tools like AWS CloudWatch can provide insights into GPU metrics. Optimize hyperparameters and model architecture to ensure that the GPU is effectively utilized without bottlenecks.
Use Spot Instances for Cost Optimization: Consider using AWS Spot Instances for training your machine learning models on SageMaker. Spot Instances can significantly reduce costs compared to on-demand instances. However, be aware of the possibility of interruptions and design your workflow to handle them gracefully.
Implement Model Checkpoints: When training large models, implement model checkpoints to save the model’s state at regular intervals. In case of interruptions or failures during training, checkpoints allow you to resume from the last saved state, saving time and resources.
Scale Resources Based on Workload: Dynamically scale your GPU resources based on the workload. Utilize SageMaker’s capability to easily scale up or down based on the computational requirements of your machine learning tasks. This ensures optimal resource allocation and cost efficiency.
Secure Model Deployments: When deploying your machine learning model using AWS SageMaker, ensure that you implement security best practices. Use encryption for data in transit and at rest, configure access controls, and regularly update IAM roles to follow the principle of least privilege.
Regularly Update SageMaker and Framework Versions: Stay updated with the latest versions of AWS SageMaker and the machine learning frameworks you use. Regular updates often include performance improvements, bug fixes, and new features that can enhance the efficiency of GPU-accelerated workflows.
Conclusion
AWS SageMaker makes it easy to use GPUs for high-performance machine learning. By following the steps outlined in this article, you can set up a notebook instance with GPU support, train your machine learning model on the GPU, and deploy it using SageMaker. Using GPUs can significantly speed up training times and enable real-time inference, allowing you to develop better machine learning models faster.
