
This article was published when data science tooling like Dask and R was a primary focus for Saturn Cloud. Today, Saturn Cloud is the enterprise AI platform for any GPU infrastructure.
As a data scientist, you will often find yourself working with JSON files. These files are widely used for data exchange between web services, and they have become a popular format for storing data. If you work with Jupyter Notebook, you can easily load JSON files using the pandas library. In this post, we will go over the steps to load a JSON file in Jupyter Notebook using pandas.
Table of Contents
- Introduction
- Why Use Pandas to Load JSON Files?
- Step-by-Step Guide to Load JSON Files Using Pandas
- Conclusion
Why Use Pandas to Load JSON Files?
Pandas is a powerful library for data manipulation and analysis. It provides a convenient way to work with tabular data, and it is widely used in the data science community. When it comes to loading JSON files, pandas offers several benefits:
- Pandas can handle large JSON files with ease.
- Pandas can convert JSON data into a tabular format, which makes it easier to work with.
- Pandas can handle missing data in JSON files.
Step-by-Step Guide to Load JSON Files Using Pandas
To load a JSON file in Jupyter Notebook using pandas, follow these steps:
JSON File:
{
"data": [
{"id": 1, "name": "John", "age": 25, "city": "New York"},
{"id": 2, "name": "Alice", "age": 30, "city": "San Francisco"},
{"id": 3, "name": "Bob", "age": 25, "city": "Los Angeles"},
{"id": 4, "name": "Eve", "age": 35, "city": "Chicago"}
]
}
Step 1: Import the Pandas Library
Before you can use pandas to load a JSON file, you need to import the library. You can do this by running the following code:
import pandas as pd
Step 2: Load the JSON File
Once you have imported the pandas library, you can load the JSON file using the pd.read_json() function. This function takes the path of the JSON file as a parameter. Here’s an example:
df = pd.read_json('data.json')
In this example, we are loading a JSON file called data.json. The pd.read_json() function returns a pandas DataFrame object.
Step 3: Explore the Data
Now that you have loaded the JSON file into a pandas DataFrame object, you can explore the data using pandas functions. For example, you can use the df.head() function to view the first few rows of the DataFrame:
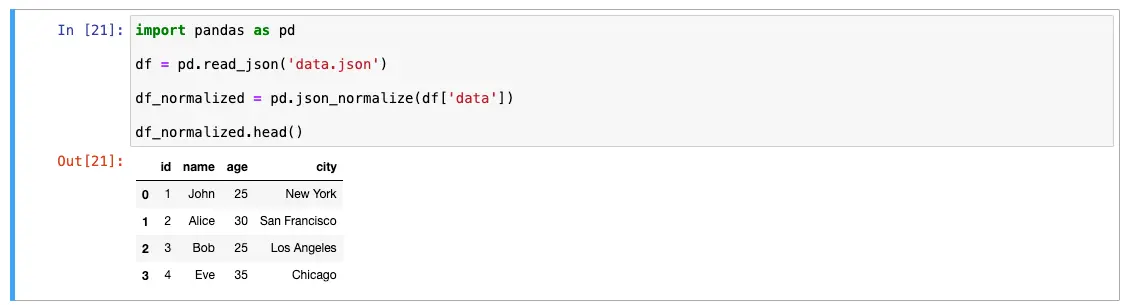
If your JSON file contains nested structures, such as dictionaries within columns, you may want to use the json_normalize function to flatten the data. This is particularly useful for handling nested JSON structures.
df_normalized = pd.json_normalize(df['data'])
df_normalized.head()
Step 4: Manipulate the Data
Once you have loaded the JSON file into a pandas DataFrame object, you can manipulate the data using pandas functions. For example, you can use the df.groupby() function to group the data by a specific column:
grouped = df_normalized.groupby('age')
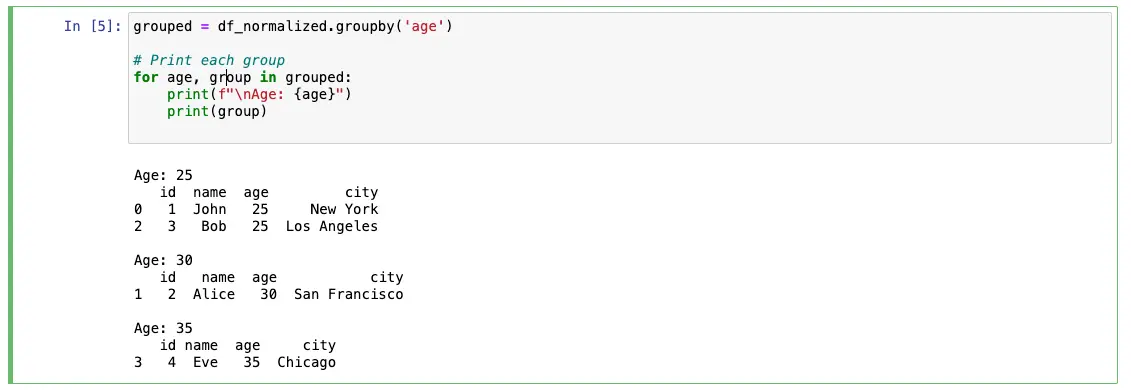
In this example, we are grouping the data by the column called column_name. The grouped variable contains a pandas GroupBy object.
Step 5: Visualize the Data
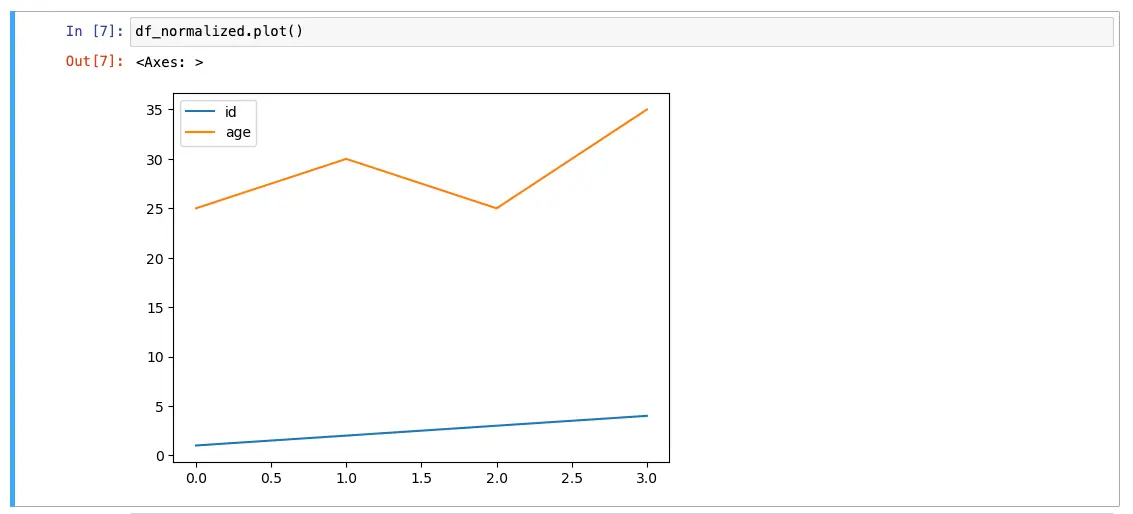
Finally, you can visualize the data using pandas functions or other visualization libraries like Matplotlib or Seaborn. For example, you can use the df.plot() function to create a simple plot:
df_normalized.plot()
This will create a simple line plot of the data.
Conclusion
In this post, we have gone over the steps to load a JSON file in Jupyter Notebook using pandas. Pandas is a powerful library for data manipulation and analysis, and it provides a convenient way to work with JSON files. By following the steps outlined in this post, you can easily load and manipulate JSON data in Jupyter Notebook using pandas.
